It seems hardly worth pointing out that the universe we live in is a highly asynchronous place: it is a place where an infinite number of things are happening all at once. In fact, it might be said that humans, and indeed all living creatures, are designed to operate in such an environment. In spite of this, until recently, computer programs were always based on the model of a sequential, "one step at a time", computer with a single instruction counter. Not surprisingly, therefore, mapping the real world onto such a model has always been difficult, and is becoming more so as the requirements on our systems become ever more stringent
Back in the '60s, Dr. Lance Miller of IBM became intrigued by this apparent mismatch, and went looking for strictly procedural behaviors in other areas of human experience. One activity that, at first sight, seems to be pretty procedural, is the act of cooking. He pointed out, however, that even cooking actually has a lot of asynchronism built in - for instance, the instruction "add boiling water" presupposes that the water has been set to boil at some unspecified earlier time. The term "preheated oven" is so common we probably don't even notice that it also violates strict sequentiality. People say and write things like this all the time without thinking - it is only if you try to execute the instructions in a rigidly serial manner (i.e. "play computer") that you may find you spend a long time waiting for ovens to heat up! In fact, synchronous, sequential procedures are among the hardest kind for humans to deal with.
How does all this relate to computer programming? To see this,
it may be helpful to step back to the early days of data
processing. In those days, most business data processing
was done using what were called "accounting machines". An
application was defined as a network of
processes, where each process was performed by a machine, and where the
data
that they accepted and generated was punched into decks of 80-column
cards.
All these machines were in fact running concurrently - performance was
dependent on how many operators there were, and how many machines they
could keep running at the same time. The networks were drawn on large
sheets of paper, and served as guides for the operators. So the first
major way of doing business applications was in fact a "data flow"
system. The analogies are even closer if you
look at how these machines were given their instructions, because the
plug-boards
used by many of them implemented data flow at an even more basic
level
(wires were used to connect the output of one register to the input of
another,
and it was the way these registers were connected that made one
application
different from another). Again, we used large sheets of paper to
specify these plug-boards, but in this case the sheets had the
registers preprinted on them, and we just connected them up as required
for a given application.
During the same period, scientists in labs were developing powerful number-crunching machines, which came to be called "computers" (originally a "computer" was a person), primarily intended for performing repetitive, mathematical calculations on large amounts of data. At first the commercial and scientific worlds were seen as rather different, and in fact had their own computer lineages (in the IBM world the 707x machines were commercial, while the 709x machines were scientific), although one of the earliest commercially successful computers, the IBM 650, a magnetic drum machine, was used for both. The IBM 1401 was primarily intended for commercial applications (it was character-based, rather than binary), and was incredibly successful. It was probably the introduction of the 1401 which signed the death warrant of the old accounting machines. However, the 1401 had only one instruction counter, so it could only do one thing at a time (I/O was synchronous on the 1401), while in an accounting machine shop there had been many different activities happening at the same time. Because high-speed storage on the 1401 was small, jobs were set up as a series of steps communicating by means of sequential files on cards or tape - initially - and later on disk. If you laid out these computational steps on a piece of paper, showing the files connecting them, the result again was a data flow diagram - but it wasn't thought of in that way!
In the early 60's, IBM introduced the S/360 series of machines - these machines had a single instruction set for both commercial and scientific work, and also ranged in size from the quite small to the very large. The ability to run a single instruction set across the whole range of machine sizes was achieved by moving from narrower (less parallel) to wider (more parallel) microcodes as you went from small to large machines. These machines had both binary and character string operations, as well as floating point (initially only at the high end), so a single instruction set could be used for both scientific and commercial applications.
All during this evolution, however, there seems to have been some concern that business applications were "more complex than they should be"... A book first published in the 1950's [1] contains the following remark:
"It always outrages pure mathematicians when they encounter commercial work for the first time to find how difficult it is." (p. 258)
and further on:
"...it is so hard in practice to get any programme [sic] right that several mathematicians may be needed to look after a big machine in an office." (p. 259).
I wonder what the authors would think if they could see one of today's computing facilities! In those days, the main barrier was thought to be the difficulty of ascertaining the exact rules for running a business. Today that issue seems relatively minor, compared with all the other challenges we meet daily in the process of getting applications up and running, and of maintaining them once they are built.
At a basic level, however, the scientific and business problem spaces really are different: mathematical applications generally deal with repetitive operations on mathematical entities (scalars, vectors, matrices), while business applications typically deal with data streams and the transformations that apply to them. One notices that business applications use relatively few mathematical functions. On the other hand, they are constantly changing, due to changing business requirements, government regulations, environment changes, and so on. This suggests that in this environment it is vitally important for code to be easy to maintain, and yet programming tools traditionally address production of new code, rather than maintenance of old. It is interesting to note that, over the years, FORTRAN has been a much better match to its problem space than COBOL has been to its problem space - in spite of the vast amounts of the world's programming work that are done in COBOL (the results of university research haven't made much of a dent in this, although this may finally be starting to change).
A common measure of complexity in a program is simply the number of if-then-else decisions. If you analyze these in a conventional business application, you find that many of these decisions are related to synchronization of data - data has to be available when it is needed, and must disappear when it is no longer needed. In a purely synchronous program, this can result in extremely complex code. This in turn means that it has been extremely hard to come up with reusable components in the area of business programming. Once you have defined a few general purpose subroutines, such as formatting, table lookup, and some conversion routines, ideas start to dry up! There are "natural" primitives in business programming, such as "sort", "merge", "summarize", etc., but these are hard to do in a synchronous program, as they tend to be "spread out" in time. The technology described in this paper, on the other hand, tends to yield exactly this kind of primitive, with very little imagination or effort required!
We are thus starting to be able to articulate a rather fundamental question: why should we constantly have to force-fit a style of application that deals almost exclusively with transformations applied to data streams, into a predominantly synchronous, procedural, mathematically-oriented computing environment? When we add to this the growing requirement for world-wide distributed operation and 7/24 availability, which put additional strains on our machines and on the very talented and dedicated people who look after them, it should not be at all surprising that we have such a hard time implementing this type of application on languages and machines that were primarily designed for a completely different problem space.
A key piece of the answer that has emerged over the last 30 years is the concepts that have been collected under the term "Flow-Based Programming". This development approach views an application, not as a single, sequential, process, which starts at a point in time, and then does one thing at a time until it is finished, but as a network of asynchronous processes communicating by means of flows of structured data chunks, called "information packets" (IPs). The reader will recognize this as having some similarities with the UNIX approach, except that the application network may be as complex as desired, and communication is by means of structured chunks of data, rather than simply characters. Actually, the data doesn't actually move - it is the ownership of the data that travels through the network. At any point in time, a given IP can only be "owned" by a single process, or be in transit between two processes. The network is defined externally to the processes, basically as a list of connections, which is interpreted by a piece of software, usually called a "scheduler".
These concepts are described at length in the author's book, "Flow-Based Programming: A New Approach to Application Development" [3], which contains a detailed analysis of how this approach to application building works, and why it is so effective. Although it is too long to summarize in a short paper, some of the more important points are described below. A web site containing much of this material, as well as some downloadable software, is accessible at http://www.jpaulmorrison.com/fbp/.
Briefly, an application is defined as a network of processes
communicating by means of fixed-capacity connections, across which
travel (not physically, but virtually) streams of data chunks known as
"information packets" or
IPs. A connection is attached to a process by means of a
"port", which has a name agreed upon between the process code and the
network definition. More than one process can execute the same
piece of code, called a "component". Thus, the IN port of a
given component can be connected to a different connection for every
process that executes that component. And, of
course, many different components can all have a port called IN.
As we said above, data is handled in terms of "information
packets", objects with a well-defined
lifetime, rather than records or areas in storage. By
"objects" we do not mean the passive objects of conventional
Object-Oriented Programming, but things much more like objects in the
real world that are created, do things, have things done to them, and
are eventually
destroyed. This fundamentally
changes the way the programmer looks at data. An example may help.
Let's compare a pure algorithmic problem with a superficially similar business-related one. We will start with a simple numeric algorithm: calculating a number raised to the 'n'th power, where 'n' is a positive, integer exponent. This should be very familiar to our readers, and in fact is not the best way to do this calculation, but it will suffice to make my point. In pseudocode, we can express this as follows:
/* Calculate a to the power b */
x = b
y = 1
do while x > 0
y = y * a
x = x - 1
enddo
return y
This is a very simple algorithm - easy to understand, easy to verify,
easy to modify, based on well-understood mathematical concepts.
Let us now look at what is superficially a similar piece of logic, but
this time involving files of records, rather than integers. It
has the same kind of structure as the preceding algorithm, but works
with streams of records. The problem is to create a file OUT
which is a subset of another one IN, where the records to be output are
those which satisfy a given criterion "c". Records which do not
satisfy "c" are to be omitted from the output file. This is a
pretty common requirement and is usually coded using some form of the
following logic:
read into a from IN
do while read has not reached end of file
if c is true
write from a to OUT
endif
read into a from IN
enddo
What action is applied to those records which do not satisfy our
criterion? Well, they disappear rather mysteriously due to the
fact that they are not written to OUT before being destroyed by the
next "read". Most programmers reading this probably won't see
anything strange in this code, but, if you think about it, doesn't it
seem rather odd that it should be possible to drop important things
like records from an output file by means of what is really a quirk of
timing?
Suppose we decide instead that a record should be treated as a real
thing, like a memo or a letter, which, once created, exists for a
definite period of time, and must be explicitly destroyed before it can
leave the system. We could expand our pseudo-language very easily
to include this concept by adding a "discard" statement, and replacing
"read" and "write" by "get" and "put", respectively. Our
program might now read as follows:
get a from IN
do while get has not reached end of stream
if c is true
put a to OUT
else
discard a
endif
get IP a from IN
enddo
Now we can reinterpret "a": rather than thinking of it as an area of storage, let us think of "a" as a "handle" which designates a particular "thing" - it is a way of locating a thing, rather than the storage area containing (a view of) the thing. In fact, these data things should not be thought of as being in local storage: they are "somewhere else" (after all, it does not matter where "get" puts them, so long as the information they contain becomes available to the program). These things also must be created and eventually destroyed - they have a definite "lifetime". The "handles" described above actually map well onto the "references" of Java and other similar languages. Furthermore, quite intuitively, if you forget to discard your IPs, they will accumulate somewhere, eventually causing some kind of resource shortage. Some languages have introduced "garbage collection" to take care of this situation, but in FBP this is regarded as the responsibility of the application designer. IPs, just like any objects that have value in the real world, have to be accounted for. Garbage collection fuzzes this distinction, and allows a sloppier level of accountability for data objects, which runs counter to the philosophy of FBP.
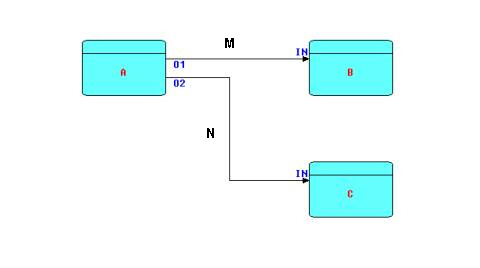
The following diagram shows the major entities of an FBP diagram (apart from the IPs). Such a diagram can be converted directly into a list of connections, which can then be executed by an appropriate engine (software or hardware).
A, B and C are processes executing code components. O1, O2, and the two INs are ports connecting the connections M and N to their respective processes. It is permitted for processes B and C to be executing the same code, so each process must have its own set of working storage, control blocks, etc. Whether or not they do share code, B and C are free to use the same port names, as port names only have meaning within the components referencing them (and at the network level, of course).
M and N have a fixed capacity in terms of the number of IPs that they can hold at any point in time. IP size may range from 0 bytes to 2 × 109. Restricting a connection to a maximum number of IPs means that a process may get suspended while sending, as well as while receiving. This is what allows an application to process a very large number of IPs using a finite (and controllable) amount of storage. It has also been shown that this prevents a problem known as "livelock".
The concept of "port" is extremely important for component reuse - it is what allows the same component to be used at more than one place in the network. Without this facility, a component would have to name its connections directly, as is the case with many of the data flow approaches that have appeared in the literature. Some approaches pass the connection name as a parameter, but we have found it more intuitive to use a separate facility.
This ability to use the same component at more than one place in the network means that FBP is a powerful reuse tool, as components can be written, tested once and then put "on the shelf", to be used in many applications. In one FBP implementation that has been in continuous use at a large bank for over 30 years, some of the earliest components are still being used for new applications, and indeed are still being continuously improved. When this happens, care must be taken to make sure that no earlier uses have been impacted. The ability to change function by just changing connections, and without having to change the insides of a component, is characteristic of real-world objects, and, in the computer field, this has been called "configurable modularity". The distinguished IBM engineer, Nate Edwards, coined this term some years ago, and stated that it is a characteristic of all systems that can truly be called "engineered".
The data traveling across a connection is called a "stream", and is being generated and consumed asynchronously - this concept thus has similarities to the "lazy cons" concept of some functional programming systems. The IPs comprising the stream naturally do not all exist at the same moment in time, so this approach can support very long-running applications, while still using a finite amount of storage.
The above-described system of connections and processes can be "ramified" to any size. In fact, we have found that it is possible to start off with a simple network, and then add more connections and processes, with only a linear increase in complexity, unlike the exponential increase that is the rule in conventional programming. This development technique also of course fits in well with many of the more popular recent development approaches, such as rapid prototyping, iterative development, etc.
Now, a major difference between such an asynchronous network and conventional procedural code is that the exact timing of events is no longer fixed: to ensure predictable processing results it is merely necessary that a given IP arrive at process B after leaving process A, and that two IPs not change their sequence while traveling across a given connection. We do not require that the exact sequence of all events be fixed in the application, as was required by the old programming algorithms. This leaves the infrastructure software free to make its own decisions about the exact timing of events - the application defines "what", not "how".
Thus we see that, at a deeper level, the emphasis in application design shifts from planning the exact sequence of atomic operations to thinking about data streams and their transformations. This view of the world, not surprisingly, scales up (and down), giving a consistent view at many levels. For instance, the higher level data flows could be documents flowing between departments of a company; the lowest level might be electrons travelling across a wire.
Any node in the network can be replaced by a subnet (a partial network with "sticky" connections) or vice versa. In addition, because there is a consistent view at all levels, during system maintenance function can be moved very easily between job steps in a batch environment or between different machines (real or virtual). The data flow way of thinking of course has a lot in common with simulation systems, so it is also possible to move back and forth between a system and a simulation of it.
All of the above suggests that this way of looking at applications is well-suited to distributed applications. Networks like the ones we have been describing do not care whether they are running on one processor or many, one machine or many, or even one time zone or many. However, it also means that programmers can no longer count on being able to control the exact timing of events across multiple systems, and indeed should not try. In our experience, such attempts usually result in poor utilization of resources anyway.
In the above-mentioned book, I devote two chapters to online and interactive applications, respectively. It is interesting that FBP supports online and offline applications equally well, and in fact this distinction, which in the past has required very different kinds of software, really becomes unnecessary under FBP. Here is a quote from Chapter 19:
"...by removing many of the old distinctions between on-line and batch, not only do programmers move more easily between these different environments, but we have found that code can be shared by batch and on-line programs, allowing large parts of the logic to be tested in whatever mode the developer finds most convenient. We have even seen cases where data was validated in batch using the same edit routines which would eventually handle it in the on-line environment. Once you remove the rigid distinction between batch and on-line, you find that a batch is just a way of managing the cost of certain overheads, just as it is in a factory, and therefore it makes a lot of sense to have systems which combine both batch and on-line. If you take into account distributed and client-server systems, you will see that there are significant advantages to having a single paradigm which provides a consistent view across all these different environments".
In a recent use of the Java implementation of FBP (described in more
detail below), we built an advanced e-Brokerage system. One of the
characteristics of this kind of system is that it has to have multiple
"back-ends" - different transactions have to be routed to different
servers which may run on different systems, sometimes in different
parts of the country. Sometimes the same
transaction will be routed differently at different times of the day.
Here
is a highly schematic layout of how such a system looks using FBP (our
actual
implemented system had a number of caches, which are not shown in the
diagram).
Note also that this diagram can conceptually be spread across multiple
systems - since the lines in the diagram are communication paths, they
can use any desired medium, from lists in one machine's memory to
camel-back!

Another consequence of the move towards high availability, distributed, applications is the need to be able to modify systems "on the fly". With FBP, it is possible to quiesce part of a network (choke off the input data flow so that IPs in process are eventually flushed, and the related processes become "dormant"), and replace components dynamically. Another technique would be to divert the flow of data to another part of the network (much like repairing a dam), make the necessary repairs on the old section, and then restart the normal flow. We owe this concept to the late Wayne Stevens, who devoted much of his impressive energy to promoting these concepts within the Information Technology industry (e.g. [4]).
The emphasis in FBP is thus on data streams and substreams, and the processes that apply to them, rather than viewing the application as a single process with the data simply a passive resource. A consistent, data-oriented, approach can be used at multiple levels of the application, just as we saw in the old accounting machine applications. Many design techniques view the application this way, one popular technique being Structured Analysis, but it has always been difficult to convert this type of design to old-style, procedural code. A characteristic of Structured Analysis is "step-wise refinement", and this maps very well to the subnet concept of FBP - one lays out the network at a high level, then progressively replaces components with subnets. In fact, as we said above, the initial versions of the components can even be simulations of the future subnets.
A piece of work that has been drawing a lot of attention recently is the Linda system, described in a number of articles by Gelernter and Carriero [2]. In Linda, components communicate by sending and receiving data chunks called "tuples", which reside in "tuple space". In FBP, IPs also reside in what could be called "IP space". A primary difference from FBP is that Linda tuples do not travel across connections, but are "launched" and later accessed associatively, by the receiver specifying some data attributes to match on. If Linda is a bus, FBP is a tram! Gelernter and Carriero stress that Linda is a "coordination language", rather than a programming language, as components can be coded in any programming language that supports send and receive. We have borrowed this term, as it clarifies the nature of FBP better than thinking of it as a language or as an execution environment. In their paper, the authors also make the point that the primitive operations of this new way of thinking are send and receive, rather than call (a call can in fact be implemented very nicely by a send followed by a receive). The actual quotation is as follows:
"In our experience, processes in a parallel program usually don't care what happens to their data, and when they don't, it is more efficient and conceptually more apt [my italics] to use an asynchronous operation like Linda's 'out' than a synchronous procedure call.... It's trivial, in Linda, [or FBP] to implement a synchronous remote-procedure-call-like operation in terms of 'out' and 'in' [FBP 'send' and 'receive']. There is no reason we know of, however, to base an entire parallel language on this one easily programmed but not crucially important special case."Linda and FBP have interesting, perhaps complementary, capabilities, and it may be that future systems will be a combination of the two.
Finally, given the growing interest in high-performance systems, it is not surprising that FBP has a direct bearing on such systems. In our first implementation of FBP, we discovered that batch jobs tended to take less elapsed time using FBP than with conventional technology. The reason for this was the "one step at a time" approach of conventional coding - even if an I/O operation is overlapped with processing, if that I/O is suspended for whatever reason, the whole application gets suspended. Under FBP, only a single process is suspended, while all others are free to proceed as long as they have data to work on, and space to put their results.
The combination of this with the configurable modularity provided by
the "port" concept gives some interesting capabilities. Here is
a fragment of a larger network:

In the above diagram, the processes marked Sn are processes executing the same code component (call it S). The process shown as LB is a Load Balancer component, which takes a stream of IPs and distributes them to the Sn processes. The ports on LB marked O[n] are elements of a "port array". This is similar to the simple ports shown above, but allows multiple connections to be attached to it. It has a "dimension" which can be specified at definition time, so that the network can be adjusted to reflect the degree of parallelism desired. When more than one output port is connected to a single input port (e.g. IN in P in the above diagram), the incoming IPs are processed on a "first come, first served" basis. It will be noted that IPs sent from LB will not arrive at P in the order in which they arrived at LB, but in most cases this doesn't matter (see the remark by Gelernter and Carriero quoted above). In many cases sorting is only required when humans have to look at data.
The use of a number of parallel processes, as shown in the diagram, can be used both when the processing is I/O-bound, and when it is CPU-bound. In earlier FBP implementations, where computers only had a single instruction counter, this type of multiplexing was mainly useful to improve I/O performance. Now that we have multi-processor computers, processes can usefully be multiplexed when they are CPU-intensive also, as different threads will be assigned to different processors, and, since FBP is naturally multithreaded, programmers do not have to do complex programming to take advantage of this feature.
The question of how FBP relates to Object-Oriented approaches has come up many times - in fact, the earliest version of FBP (which appeared in the early '70s) has sometimes been characterized as one of the very first OO systems. A detailed comparison, with programming examples, is given in the book "Flow-Based Programming", but a key difference is that in FBP communication between components is via data chunks (IPs), whereas in what may be called "conventional OO" it is via an indirect call (through the class of the target). At least one system, Smalltalk, uses the term "message" to describe what is actually a linearized indirect call, but true messaging systems require multiple asynchronous threads or processes.
In conventional OO, objects have autonomous data and logic, but the timing of method calls is controlled from outside. In our experience, and that of a number of other writers on this subject, it is very difficult to build complex systems on this framework. The missing factor is autonomy of control. Interestingly, more and more message-oriented systems seem to be emerging as people realize the inadequacy of the older approach. Enterprise Java Beans (EJBs) have recently been integrated, in their latest specification, with Java Message Service (JMS) to create a "message-driven bean" [6], which, in my view, moves EJBs much closer to the FBP paradigm.
In an early paper, Ellis and Gibbs, in Kim and Lochovsky's 1989 book [5], describe what they call "active objects", which bear a strong resemblance to FBP. To quote Ellis and Gibbs:
"Although we foresee that object-oriented programming, as we know it today, is close to its deathbed, we foresee tremendous possibilities in the future of active object systems.... Vive l'objet actif."In fact, FBP and OO are not fundamentally incompatible - one can build a very elegant flow-based system on top of an OO base. A powerful FBP implementation is now available, written in Java, using Java Thread objects, in conjunction with the synchronized and notify primitives. In fact, as we said above, the concept of ownership of IPs described above maps elegantly onto Java references.
Not surprisingly, the concepts described above are a good match with many of the leading edge concepts in the IT industry. Some of these are discussed in two chapters near the end of my book. Examples that come to mind are: IBM's MQSeries, which can link heterogeneous systems together, "worms", "agents", "knowbots", massively parallel computers, and many others.
This summer (2003), it is beginning to look as if it might be "steam-engine time" for the concepts described above. "Steam-engine time" refers to the idea that, when it is time for steam engines to be discovered or invented, they will be discovered or invented by a number of people independently. Some concepts that seem to me to belong to the same general family as FBP are "microflows" and "Service-Oriented Architectures" (SOAs), and, possibly, IBM's WSFL, but a discussion of these concepts would make this paper far too lengthy.
One other development is that the new UML standard, UML 2.0 [7], will apparently support ports. Here is a quote from the cited article:
A port connects a class’s internals to its environment. It functions as an intentional opening in the class’s encapsulation through which messages are sent either into or out of the class, depending on the port’s provided or required interfaces.A port that has a "provided" interface would be called an input port in FBP terminology, while one with a "required" interface would be an output port. Apparently, the new standard will also allow bidirectional ports, but FBP has never needed this feature, and I shall be interested to see how popular this feature turns out to be in practice. The friend who told me about this wrote the following in a note to me: "I thought you might be amused and stimulated by the 'discovery' of these needed additions to OO constructs which you anticipated many years ago."
Before I close, I would like to address a question that comes up frequently: the size and complexity of typical FBP networks. This is clearly related to the question of the "granularity" of components, which in turn relates to the overhead of the infrastructure. The faster and leaner the overhead of sending and receiving information packets, the more processes one can have in a network. Conversely, systems that tend to make heavy weather over transmitting data tend to have large, complex components. I have found a good rule of thumb for predicting performance is that run time is roughly proportional to the number of sends and receives times the number of information packets passing through the busiest path in the network (this may be thought of as similar to the "critical path" in a critical path network).
If the granularity is too fine, as for example in systems that treat every atomic value as an information packet, the overhead will be prohibitive on any real-world machine, plus you will pay additional overhead, at least in non-mathematical applications, trying to reassemble data objects that you have disassembled to take advantage of the parallelism.
In our experience, typical networks using the FBP implementations done to date seem to average around 40-60 asynchronous processes, constituting a single executable application, typically a single job step in a batch application. The following describes some batch applications that were built using the first FBP implementation, known as AMPS, for a major Canadian bank about 30 years ago, and which have been helping to support the bank ever since. I have chosen these because they have been maintained over the course of about 30 years, so that they may be expected to have somewhat stabilized in size.
One major application is the "Update Customer Report File" program (known as UPD). This program comprises 38 asynchronous processes, 39 classes of data object (AMPS supported classes years before Object-Oriented Programming appeared on the scene), and 65 inter-process connections (note the ratio of connections to processes - this is not a highly-connected network). AMPS has efficient storage management, which allows run time to be traded off against memory, so UPD has been tuned to use approximately 8 megabytes of storage. UPD is executed 6 times (once per region) every night, by the end of which time all of the bank's roughly 5-6 million accounts will have been processed, and UPD has always performed, and is still performing, extremely well. Another batch application, also written using AMPS, processes all the "back items" (transactions) for the entire bank in a single job step - it has a comparable size and complexity to UPD. It is probably safe to say that these applications could not have been built, nor, if we had been able to build them successfully, could they have been maintained, for more than 30 years, using conventional (control flow) technology.
AMPS was also used for a large number of "Data Base Integrity" (DBI) scans, which took advantage of FBP's ability to multithread and so make efficient use of the machine's resources. One such DBI program scans the on-line Customer Account File, currently occupying several dozen disk packs, looking for broken or inconsistent data chains. These chains are on a separate set of disk packs from the basic account data, and each customer account has a number of chains containing different types of optional or repeating item - occasionally these chains get damaged, resulting in effective loss of data. When such a situation is detected, remedial action must be taken.
This particular scan is configured to have 15 processes that read the basic account packs concurrently (one process per pack) and in turn are connected, via a single Load Balancer process, to 40 Chain Follower processes, running in parallel, which step through the chains of optional or repeating items. The Chain Follower processes are reentrant, like all AMPS modules, so can all be executed concurrently. There are a total of 73 inter-process connections. The reason for the large number of Chain Followers is that this process is extremely I/O-bound, so that some of them can always be scheduled for execution, even if most of them are waiting for I/O to complete. As data volumes change, such programs can easily be reconfigured to maintain optimum performance.
The Java e-Brokerage application referred to above had somewhat fewer processes, although a number of processes were multiplexed for the reasons given above, and much of the data was cached, for which we used separate (reusable) components. However, the number of processes would probably have grown somewhat during the life of the application, as business functions were changed or enhanced.
To sum up, in Flow-Based Programming we have a significant paradigm shift in the way we do business programming. A number of its basic concepts are now being taught in universities, but in a different context. When these concepts are used on a day-to-day basis, and accepted as the basic business programming paradigm, not merely as an afterthought on what is fundamentally still a sequential, synchronous way of looking at the programming world, I am convinced, based on almost 30 years of experience using them, that they have the potential to revolutionize the way business systems are constructed and maintained, resulting in applications that are more efficient, of higher quality, more maintainable, and more responsive to customer needs.
Bibliography
[1] "Faster than Thought, A Symposium on Digital Computing Machines" (Ed. B.V. Bowden, 1963, Sir Isaac Pitman and Sons, Ltd., London, England, 1st Edition 1953 )
[2] D. Gelernter and N. Carriero, 1992, "Coordination Languages and their Significance", Communications of the ACM, Vol. 35, No. 2, February 1992
[3] J.P. Morrison, "Flow-Based Programming: A New Approach to Application Development" (van Nostrand Reinhold, 1994), ISBN: 0-442-01771-5
[4] W.P. Stevens, 1985, "Using Data Flow for Application Development", Byte, June 1985
[5] W. Kim and F.H. Lochovsky, 1989, "Object-Oriented Concepts, Databases, and Applications", ACM Press, Addison-Wesley
[6] Enterprise JavaBeans (TM) Specification, Version 2.0 , Proposed Final Draft 2, Sun Microsystems, 2001
[7]Architecting Systems with UML 2.0, Morgan Björkander and Cris Kobryn, July/August 2003, IEEE Software