This chapter has been excerpted from the book "Flow-Based Programming: A New Approach to Application Development" (van Nostrand Reinhold, 1994), by J.Paul Morrison. A second edition (2010) is now available from CreateSpace eStore and Amazon.com. The 2nd edition is also available in e-book format from Kindle (Kindle format) and Lulu (epub format). To find out more about FBP, click on FBP.
For definitions of FBP terms, see Glossary.
|
Material from book starts here:
An increasing number of computer applications are interactive - that is, they have to communicate with an end-user, with the result that some (but not necessarily all) application processes must be geared to the pace of the end-user. An end-user will enter commands and data on a screen, select among options, etc., and results will be displayed on the screen. Usually these events alternate, but some displays occur unexpectedly, and the user must also be able to interrupt processes or switch to other activities. Hardware and software environments vary: the screens may range from "dumb" terminals to graphics terminals to programmable work-stations with powerful logic capabilities; terminals may be connected in various ways to the host; and finally the host may be running different software platforms (e.g. IBM's CP/CMS, TSO, IMS or CICS), or 4GLs based on them. While it is hard to generalize between all these variations, we can say with some assurance that there will always be a need for a program to be able to present text, numeric and alphameric information to a screen, and for the user to be able to send commands and data to the computer. There is also a need to format a screen, including specification of fixed or user-specifiable information on one or more screen and window layouts. The user and program must further be able to select among different such layouts.
In Chapter 14, I talked about "loop"-type networks supporting one interactive user (as in the IBM TSO and CMS environments), and how this changes when we move to multi-user environments such as IBM's IMS/DC (of course, TSO and CMS support multiple users, but in their case a whole program is dedicated to a single user, while an IMS/DC program supports a series of different users one at a time). In what follows, we shall go into more detail on IMS/DC, and also concentrate on one type of screen, the 3270 (without graphics capability). I believe these concepts generalize well to other environments, even to the new GUI-style interfaces with drag 'n' drop interaction (by assigning a different process to each window), but this chapter would get much too long if we tried to cover even just the IBM host environments!
First I want to describe at a high level how TSO (or CMS), CICS and IMS/DC differ. By the way, IMS/DC is now IMS/TM, but I will continue to use the older term. The basic problem they all address in different ways is how to trigger program activity as a result of a user action on a screen or keyboard. In TSO (or CMS), the user has a whole program dedicated to his or her use, which multithreads with other such programs. During his or her "think-time", the program has to wait, but the other parallel programs (either supporting other users, or running batch) can use the available CPU time.
CICS and IMS/DC are both very popular for IBM hosts, and they are both delivering very respectable transaction rates. Traditionally, CICS has had lower overhead but provided less protection between users. These distinctions may be breaking down as these systems evolve. In the case of CICS, CICS runs a number of parallel tasks. When one of these tasks is triggered by a user's action, it executes the appropriate logic. After output has been generated, the task can be suspended ("conversational" processing), or can terminate after user-oriented information has been saved ("non-conversational"). If all code was conversational, a CICS program could only support as many users as there are tasks, so this mode is not recommended - especially since human think-times are long compared with the CPU time required by the machine. CICS, like all FBP implementations so far, can suspend a task at any API call. In fact, allowing tasks to be suspended elsewhere than at an API call would make FBP (and CICS) programming much harder, so it is unlikely that this will change. I have always felt that the internal logic of CICS is so similar to that of FBP that a hybrid system combining ideas from both might be extremely interesting.
IMS/DC also uses a number of parallel programs, but, unlike TSO, each program services multiple users, one after the other - each user "occupies" a program from the time a screen or keyboard action takes place until the response has been sent back to the screen, at which point the program is free to service a different user. In fact an IMS program cannot wait for the user to finish thinking - if there is no work waiting to be done, it just terminates. So IMS/DC cannot use CICS's "conversational" approach - while it also uses the term "conversational", it has a different meaning. Also IMS programs run in separate regions, so they can interrupt each other preemptively; whereas CICS tasks can only lose control at an API call.
IMS transactions are driven from a "message queue". Each message was added to the queue as a result of a user taking some action, such as hitting ENTER, a Program Attention key or a Program Function key at his or her terminal. IBM 327x terminals are "buffered", meaning that information is accumulated on the screen until one of the above keys is hit, at which time all modified data is sent to the host, together with an indication of what action was taken by the user, and where on the screen the cursor was. All this information is collected and put into an "input message", which is then placed on the message queue. In addition each message contains an 8-character code indicating which processing is to be applied to this data. Very often it is used to identify the screen which was being displayed when the interrupt occurred, allowing the program to select the processing. This code is called the "transaction ID".
The transaction ID is used by IMS to select, based on rules the installation has specified, which of a set of programs, called "message-processing programs" (MPPs), is to service this transaction. The MPP may already be running: if not, it will be started in an available "message-processing region" (MPR).
When program logic decides that a new screen is to be displayed on the terminal, an "output message" is put on the message queue by the transaction, containing the data to be displayed and the position at which the cursor is to be positioned. The program usually specifies which screen layout is to be used for this.
An MPP processes serially the transactions it is supposed to handle. It continues picking its transactions off the message queue and putting output messages onto the queue until one of the following occurs:
-
there are no more transactions waiting
-
a higher priority transaction needs the region
-
it reaches a predefined limit called the "program limit count" (PLC).
When one of these occurs, the MPP's command to get the next transaction fails with a specific return code ('QC').
Now note that the MPP serially processes transactions from different users, rather than being dedicated to one user. Also a given user's interaction with the host (main-frame computer) will jump about from one screen to another, and therefore from one MPP to another, and therefore from one message-processing region (MPR) to another. This means that any information which has to be carried from one screen of such a "conversation" to another has to be held on disk, or in a storage area which is reserved for that one user (IMS provides such an area, which is called the "Scratch-Pad Area", or SPA). Some applications also use the message itself for this kind of information, as not all the message information actually has to be displayed on the screen.
While there are a number of other types of IMS/DC application, such as WFI, pseudo-WFI, etc., the above sketch will suffice to give a background for building on-line applications using FBP.
Note that the term "transaction" in IMS is quite ambiguous - we will try to avoid using it since the terms "MPP" and "input message" cover most of its meanings. One other usage of the term "transaction" means the processing within an MPP which runs from the reading of an input message to the writing out of an output message. This processing is dedicated to a single user and hence it is important that no data belonging to another user be picked up inadvertently, even though a given MPP may service a number of users before it terminates.
An interactive application differs from a batch one primarily in that some (not necessarily all) of its logic is synchronized to the speed of the user. If you visualize an interactive application as an alternation of screens and processes, the screens can themselves be treated as processes whose job is to convert between internal and external data formats. Of course, these processes also allow selections to be made from menus and lists, plus requests for certain general services, such as Help or Return to Previous Screen.
Let us use a very simple application consisting of 3 screens as an example. Diagramming the flow between screens, we get:
where S01, S02 and S03 are screens
A, B and E represent user actions
L1A, L1B, L1E, L2E and L3E represent logic
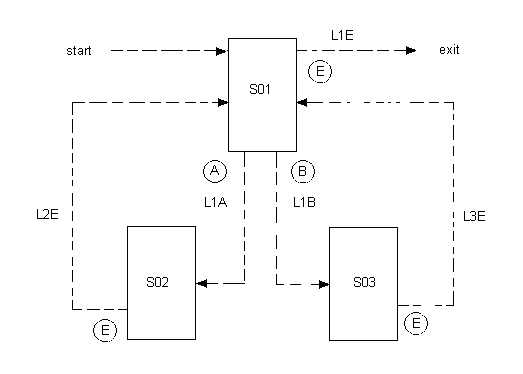
(user actions are commonly either PF keys being pressed or commands being entered)
Figure 19.1
The next stage is to convert all the screen blocks to processes and add in the logic processes (plus one to start the network). This gives us the following diagram:
where S01, S02 and S03 are screen processes
A, B and E represent user actions,
L1A, L1B, L1E, L2E and L3E represent logic processes
Figure 19.2
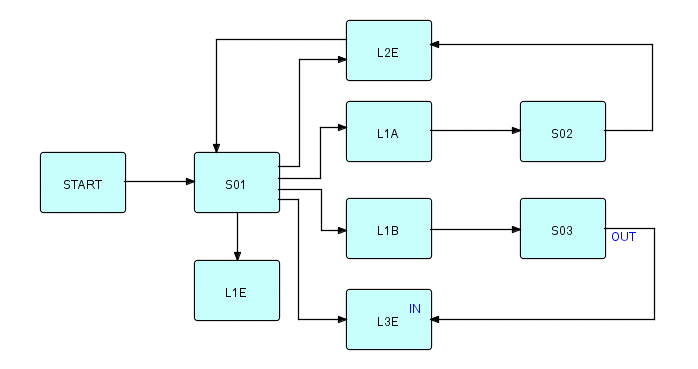
In the above diagram, the screen processes must output the IP streams which the logic processes expect, and logic processes must output the streams which the screen processes expect. In designing the application, the designer must coordinate the screen designs, IP streams and logic processes.
There is another consideration: a typical application may have quite a few different screens and expert users increasingly want to be able to jump from any screen to any other, without being required to go up and down through menus. In other words, the network becomes more and more thoroughly interconnected. Through all of this, the designer must make sure that each screen process gets the data it expects. Just as with batch applications, it is best for the designer to concentrate on the data flows, rather than on the processes.
Now, if the network structure reflects the possible paths between the screens, it is clear that it will become more and more complicated as the connectedness between screens increases. You could eventually get a network where every process is connected to every other process, so that the network no longer provides any assistance to the developer in understanding what is going on. Instead of using the network to define the flow between screens and logic, we have found that it is much better to do this with a table. This table specifies the screens and processes resulting from each possible combination of screen displayed and user action taken. This will allow the application to be "grown" in a natural way, without a corresponding increase in network complexity. The network shape arising from this approach actually becomes simpler, as we will have moved much of the complexity into a table. The network topology will now usually be a loop, comprising processes to display a screen, analyze the user action, trigger any processes, select another screen, and so on.
In conventional batch programming using data flow, the flow of data, and therefore the sequence of data transformations, is predominantly in one direction across the network. This kind of topology arises from the fact that there is no real-time interaction with human beings. The program is started by means of JCL or by an operator command and runs until all the data has been processed.
Increasingly, however, we require programs to interface to human beings, and therefore there will be at least one process in a network that is "paced" to the speed of the human interface. In a batch FBP network, as we have seen above, all of the processes run asynchronously. In an on-line application, a network topology that appears in a number of situations in one-user operating systems, such as CMS and TSO, is the "loop-type" network. We talked about loop-type networks in Chapter 14, so you are already familiar with how these work.
Here is a diagram of such a network:
where SM is a Screen Manager
ST starts the network as a whole
the dotted line represents logic processes
Figure 19.3
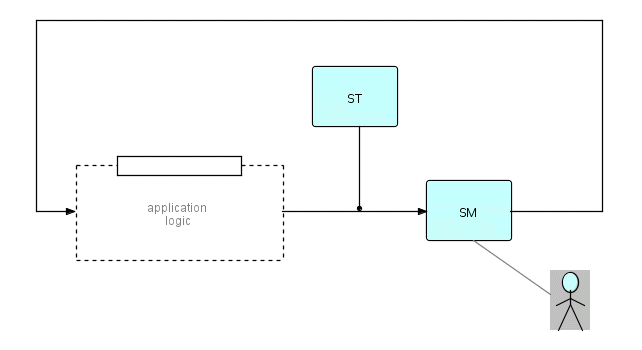
In this network, there is one process, the Screen Manager, which controls the user's screen. An IP (or group of IPs), conceptually similar to the token in a token-ring type of LAN, travels around the network triggering processes to execute. The bracket IPs provide a convenient way of grouping IPs for this kind of function - typically, we use the first IP of each substream for such information as screen name, name of key struck, position of cursor, etc., and the remaining IPs, if any, for the data. When the substream arrives at the Screen Manager process, it triggers the display of data on the screen, waits at that process until the user responds, then proceeds to the next process in the loop. The data IPs, if any, will hold the data to be displayed on the screen, and will receive any data that the user enters on the screen. The first, or "request", IP can also contain an indication of which key was pressed to tell the Screen Manager that the user has responded (e.g. function key, enter, etc.), where the cursor is and perhaps also which fields were modified (this information is often of interest to the host application).
The next process in the network will usually be a process which analyzes the response and takes appropriate actions, perhaps routing the request IP (with its accompanying data IPs) to a process which will do the appropriate application processing.
Eventually the application logic will request that another screen (or the same one again) be displayed, and the request IP will be sent back to the Screen Manager to achieve this. This then is a very standard topology that you will often run into when building interactive applications in one-user environments.
We now have to convert this type of logic into IMS transactions. We shall see that IMS transactions are also loops, but the function of the loop is slightly different.
We have seen above how a data IP can be associated with a request IP and then act as a carrier for the screen's variable data. If we temporarily ignore the request IP and simply picture the data IP triggering a screen display, we see that this is very much the way an IMS transaction asks for a screen to be displayed: an IMS "output message" containing the data to be displayed is generated by the program and is sent to the message queue. This signals IMS/DC to display a screen (conventional programs specify the screen name using a call). When the user responds, IMS/DC places an "input message" on the message queue. Soon afterwards, a transaction is triggered and the transaction program code, the MPP, gets the message from the message queue and processes it.
Let us take as an example the screen flow that we used above. Look at Figure 19.2, remembering that the boxes represent screens, not processes. Each screen in this diagram, plus its downstream logic, now potentially becomes a separate transaction. We have to convert the above screen diagram into IMS transactions by "cleaving" each box representing a screen into two pieces: an "output" piece and an "input" piece. This leaves us with a number of "batch-like" networks, with a screen input process on the left, and one or more screen output processes on the right. It is IMS/DC which provides the linkage between them. These screen handling processes appear to the transactions just the way File I/O appears to a batch program.
Another way of thinking about Figure 19.2 is that each "screen box" in this diagram is in fact a process which writes to the user's terminal, waits for a response and then sends the input from the terminal onwards (it is the "complement" of a logic process). Such a process can thus be split into two processes: one to put out to the terminal and one to get from the terminal. In between these two functions, it is too expensive in the IMS environment (unlike one-user environments like CMS and TSO) to have the whole region wait during the user's "think-time", so we essentially terminate the section of code processing that user, and restart another transaction when he or she finishes thinking and takes some action. (As we said above, ending a transaction does not necessarily mean ending the MPP). The result is a set of "batch-like" networks, with Screen Input at one end and Screen Output at the other.
The following diagram shows a single "screen process" being split into separate output and input processes:
where SO (Screen Out) puts information out to screen
SI (Screen In) gets information back from screen
Figure 19.4
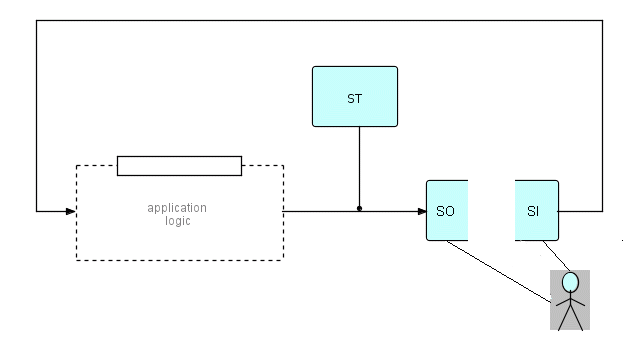
If you look at the "loop" in the above diagram, you see that it is topologically a straight line starting with SI and ending with SO. Each of these "opened up" loops becomes a separate message processing transaction.
Here is a diagram of a number of IMS transactions resulting from cutting up the screen flow shown in the above example:
where SI (Screen In) handles IMS input messages
SO (Screen Out) handles IMS output messages
R is a Selector which decides whether L1A, L1B or L1E
is to be given control
L1A, L1B, L1E, L2E and L3E are instances of the logic
"legs" in the previous diagram
Figure 19.5
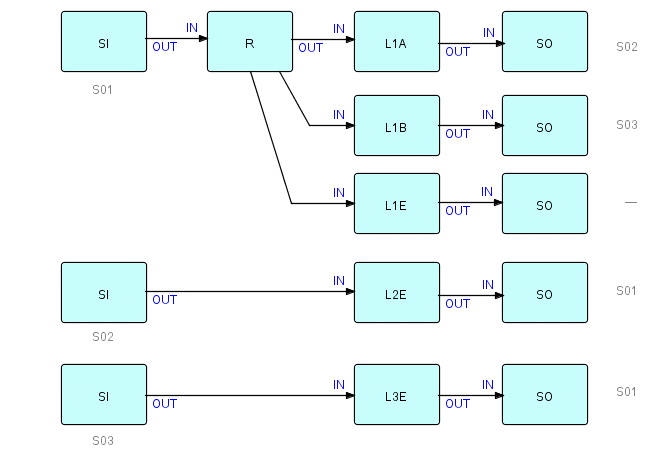
In this diagram I converted the application logic into a network structure. Clearly, this would not result in a very maintainable application - as I said above, it is much better to use a single network, and encode this kind of information in tables. Just as, in an earlier chapter, we did not want to encode the number of Canadian provinces into the network structure, we should avoid imbedding the screen flow into the network structure.
To keep the structure flexible, we will need to hold the output screen name or transaction ID in the "request IP", and allow this to trigger the display function. This allows us to have a single instance of SO which is completely general, and will dramatically simplify the transaction networks. In the IMS/DC environment, SO will use this information to select the next screen to be displayed. Of course, the data being presented to SO must match the specified screen, but this is easy to control because the screen name will be in the same substream as, and followed by, the data that relates to it.
As I said above, the loop topology turns up again, but with a slight twist, when we actually try to build an MPP using FBP. The reason for this is that MPPs are normally coded so that they check (using an IMS "get" call) if there are any more messages waiting to be processed before they close down, and it is this check which provides the "sync point" which causes the screen to be displayed and files to be updated. It is not essential for the MPP network to "loop back" but in this case various expensive types of overhead would have to be repeated for every single message. Accordingly, MPPs are usually written so that they loop back to check for more input. Remember, each time through the loop, the MPP services a different user. On the face of it, it would seem that a straight left-to-right topology would be adequate for an MPP, but this will likely result in a second message being read before the previous message has been displayed, and the above-mentioned function of the "get" as a sync point absolutely requires that inputting a message not be allowed to happen before any data base records have been modified and the output message has been written - hence the reemergence of the familiar loop-type topology.
The FBP network for an MPP now looks like this:
where SI is a process which handles IMS input messages
SO is a process which handles IMS output messages
ST starts the network
'logic' represents application logic
'exit' indicates that SI may bring down the whole
network if there are no more messages waiting
or the PLC has been reached
Figure 19.6
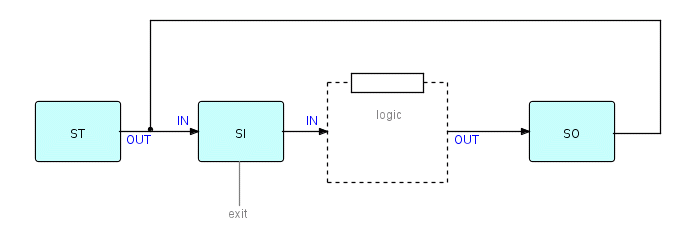
Note that, unlike the CMS or TSO case, each iteration around the loop may involve a different user, so the discipline of reentrant coding is particularly important here.
In DFDM we developed components for the functions shown as ST, SI and SO, although these were not part of the DFDM system as it was marketed. These provided an environment which allowed the intervening logic to be coded as though it were simply processing records from a file. In addition, SI and SO collaborated to support a single message format only for a given screen, instead of two separate ones (input and output) as presently required in IMS. To explain this a little further: while an IMS output format requires all variable fields which may be displayed on the corresponding screen, the input message format only contains the fields which the user may change. People often get around this by telling IMS that even the protected fields have been modified (the screen has an attribute which lets you force the "modified" flag on for a field), but this results in more data traffic between host and terminal than is necessary. Instead, let's make SO save the output message in the SPA or in a user data base, and change SI to use that information both to create a "complete" message, and also to report on which fields have actually been modified. We now have a pair of collaborating components which make the job of handling IMS messages significantly easier!
Analogously to the paradigm shift we saw in batch, FBP also forces a shift from concentrating on screen layouts to concentrating on IP layouts. For a given screen in IMS, there will in general be three layouts: the "in-storage" format, the input message and the output message. However, it is possible to combine these down to two or even one layout, by using the MFS MFLD macros to act as a "bridge". Designers of IMS applications don't generally realize that IMS MFS allows the sequence of fields on the screen to be quite different from the sequence of fields within the area in storage containing the data. This will also allow the same data IP to drive a number of different screen layouts, which is a useful characteristic in on-line systems. One might also, for example, want to use a single data IP and show different parts of it, depending on the authorization level of the user.
One last topic that is relevant to the design of on-line applications in IMS/DC is that of storage of information within a "conversation" (the suite of transactions interacting with a single user to do a job of work). I mentioned above that we can use the message, Scratchpad Area (SPA) or disk storage. The problem with the SPA from a modularity point of view, is that information in it has to be accessed by offset - i.e. one declares a structure to describe the SPA, and all transactions participating in a conversation have to use the same layout. So you essentially have an entity, the "conversation" (not otherwise recognized by IMS), which is tied to the SPA layout. If you then want to share transactions between conversations, you constrain them all to share the same SPA layout. This is another form of the "global" problem. Since FBP forces modularity, we have to find a way around globals, and we did in one of our applications this by storing data associatively in a storage area associated with the user - initially the SPA and later a special data base) - using data areas chained into a list and identified by 8-character names. We defined three components [reusable code modules], which could be used at will in the application networks. We could call these Input from Area, Output to Area, and Free Area. When we wanted to store a piece of data for later use, we simply sent it with an identifying name to an occurrence of an Output to Area component, which either replaced the data in an existing area of the same name, or created a new area. Input from Area was used to retrieve data, given an area name. The interesting thing was that (apart from Free Area) these behaved exactly like I/O components, and allowed us to maintain the "mini-batch" metaphor in the logic processing within a transaction.
There is (was) also another breakdown of modularity in IMS: namely the layout of the PCB List. Originally, IMS and transaction code had to agree on the sequence of the PCBs in the list, and the only way code could reference a PCB was by its position, so every subroutine in a transaction had to "know" the same PCB List layout. Again this made sharing subroutines between transactions very difficult. To solve this, DFDM provided a "locate PCB" function as a basic service, allowing PCBs to be located using the DBD name. IBM has since recognized this problem in IMS, and now provides the AIBTDLI interface, which allows PCBs to be referenced by name (you will remember that FBP ports went through a similar evolution from numbers to names).
One last topic I want to touch on is DB2 - it is appropriate to discuss it in a chapter on designing online systems. The relational paradigm is very powerful, and is very compatible with FBP's concepts - in FBP it is very straightforward to specify an SQL request in a component and then have it turn the rows of the resulting table into a stream of IPs. We have seen in Chapter 11 how we can attach information about "nullness" to IPs - this is a natural match with the "null" concept of DB2. We can even use the DESCRIBE facility of DB2 to generate IP descriptors automatically.
While in many ways DB2 is a marvellous system, it also suffers from what I have called a breakdown of modularity. In hindsight, it would have been better if its interfaces had been designed to be used in black boxes - unfortunately its designers did not foresee the need to use DB2 inside asynchronously executing black boxes, but we have found ways to live with this omission, so overall the two systems work pretty well together!
DB2 differs from most computation-oriented programming languages in that any components which contain SQL statements have to be precompiled as well as compiled, resulting in a separate type of output called a Data Base Request Module (DBRM). DBRMs are combined or "bound" (much as components are link edited) into what is called a "plan", which is required at run-time. One of the really nice things about using DB2 in an FBP environment is that the whole network only needs to be rebound when a coroutine issuing SQL statements has to be recompiled (re-precompiled, actually). If you therefore write all your Static SQL components and compile and bind them into a "plan" early in the development cycle, you can add logic and other functions incrementally without ever having to rebind your application plan.
The major problem we ran into was that the DB2 "cursor" (the "pointer" which programs running under DB2 use to step through a table) is not a variable, so it cannot be moved around or passed to subroutines. So you can't do a SELECT in one component, and the related UPDATE in another one. In FBP we can get around this problem by using a single component to do both actions, either by using two separate input ports or by using a single input port with two different types of request IP.
The other problem is that there is only one DBRM for a component per task, so only one cursor, so a single component doing cursor-type SELECTs cannot run asynchronously with itself in the same task, unless you give it multiple cursors (we did that experimentally - if the component needs a cursor, and finds the current one busy, it just grabs the next one). Alternatively, we could eventually develop means to automatically generate the code for this kind of component as required. Dynamic SQL does not suffer from this limitation, but it provides weaker security, so most installations prefer to use Static SQL.
Last, but probably not least, when preparing a component to run under DB2, you have to specify at link-edit time whether the program is to run under TSO or IMS. This means that a component cannot be "ported" from TSO to IMS or vice versa in load module form unless it is relinked at its destination.
I'd like to close this chapter by addressing an argument which you may hear from time to time - namely that batch is dead, and that everything can now be done on-line and therefore synchronously. As you have been reading the foregoing pages, you may have been wondering what the relevance of data streams and components like Split and Collate is to today's interactive applications. For a while I also believed that FBP was less relevant to interactive systems than to batch, but as we built more and more on-line systems, we found that the benefits of reusability and configurability are just as relevant to on-line as they are to batch, if not more so. In fact, by removing many of the old distinctions between on-line and batch, not only do programmers move more easily between these different environments, but we have found that code can be shared by batch and on-line programs, allowing large parts of the logic to be tested in whatever mode the developer finds most convenient. We have even seen cases where data was validated in batch using the same edit routines which would eventually handle it in the on-line environment. Once you remove the rigid distinction between batch and on-line, you find that batch is just a way of managing the cost of certain overheads, just as it is in factory, and therefore it makes a lot of sense to have systems which combine both batch and on-line. If you take into account distributed and client-server systems, you will see that there are significant advantages to having a single paradigm which provides a consistent view across all these different environments.