This chapter has been excerpted from the book "Flow-Based Programming: A New Approach to Application Development" (van Nostrand Reinhold, 1994), by J.Paul Morrison. A second edition (2010) is now available from CreateSpace eStore and Amazon.com. The 2nd edition is also available in e-book format from Kindle (Kindle format) and Lulu (epub format). To find out more about FBP, click on FBP.
For definitions of FBP terms, see Glossary.
|
Material from book starts here:
[This chapter has been changed to reflect changes in the way
automatic ports are handled in JavaFBP and C#FBP. It turns out that there were some logic errors in the way
checkpointing is described here - please refer to the corresponding chapter in the 2nd edition.]
We will start off this chapter by talking about how to synchronize events in an FBP application. After having stressed the advantages of asynchronism so heavily, it may seem strange to have to talk about strategies to control it, but there are times when you simply have to control the timing of events precisely, so it must be possible to do this. It is just that we don't believe in forcing synchronization where it isn't required. We have already seen various kinds of synchronization, such as loop-type networks and composites, so let us look at synchronization a bit more generally.
Typically we synchronize something in a process to an event elsewhere in the processing logic, or to an event in the outside world. Only certain events in certain processes need this treatment - it would be against the philosophy of FBP to attempt to synchronize a whole network. That belongs to the old thinking - in fact, writers on distributed programming often show a certain nervousness about not knowing exactly when things will occur. It used to be considered necessary to synchronize commits on two different systems, but we are beginning to realize that it may not be possible to scale up this philosophy across an entire network in an enterprise. In fact, IBM has recently announced a set of Messaging and Queuing products [MQSeries] which provide asynchronous bridging between all sorts of different hardware and software. A basic assumption of this software is that applications cannot, and should not, try to enforce events to be synchronized across multiple systems.
The most basic kind of synchronization is synchronizing a point in the logic of a process to a point event in time. In IBM's MVS, this is implemented using POST/WAIT logic. This involves a thing called an "event", which may be in one of three states:
-
inactive
-
being waited on
-
completed
Only one process can wait on an event at a time, but any process that knows about it may "post" it, thereby changing it to completed. If a process issues a "wait" when the event is inactive, it is suspended on that event, and the event is marked appropriately; if the event has already completed, the process that needed to know about the event just carries on executing. MVS uses this concept for its "basic" I/O: a process starts an asynchronous read or write channel program going and then continues executing. When, some time later, it needs to know whether the request has completed, it issues a "wait", and either is suspended or resumes execution, depending on whether the asynchronous I/O routine has posted the event complete or not. Thereafter the event would show complete until it is set back to one of the other states, presumably by the requesting process. All dialects of FBP except THREADS [this was written before JavaFBP and C#FBP - they do not have this facility either] have implemented an event-type wait service to suspend a single process. A nice feature of the FBP environment from a performance point of view is that one or more processes can be suspended on events without suspending the whole application. The application as a whole is only suspended if no process can proceed and at least one process is waiting on an event (if there are no processes waiting on events, you've got a deadlock). We found that applications with many I/O processes often ran faster than if they were coded conventionally using buffered I/O because, in control flow [non-FBP] coding, only one I/O is logically being executed at a time, so if it suspends, the whole application hangs.
Instead of a point event, we might instead have to synchronize an application to a time of day clock, e.g. "run this job at 5:00 p.m." All you need is a process which sends out an IP at 5:00 p.m., every day (or you could arrange for it to send out IPs every hour on the hour, or every five minutes, or every 20 seconds). Such a process can act as a clock, just as the clock in a computer sends out pulses on a regular schedule. These IPs can then be used to start or delay other processes.
Similarly to the "wait on event" service available to its components, DFDM also had the ability to suspend a process for a specified amount of time or until a particular time of day. This used the facility provided by MVS to post an event at a particular time. In the case of DFDM, this function was only provided as an off the shelf component: it could either delay incoming IPs by a certain amount of time, or generate a stream of IPs at given intervals. Where multiple time intervals were required, you could have as many of these processes as you liked in a network (DFDM kept track of which one was due to go off next).
Another kind of synchronization referred to already is the need to delay something until a process has completed. In DFDM, any unused output port would automatically present end of data to its downstream process when it closed down. In THREADS the same thing applies, or you can use automatic ports if you want to automatically generate a signal IP when a process deactivates. [In JavaFBP and C#FBP, only the latter technique is available, with the closedown signal being generated at termination, not deactivation time.] Imagine that you want to delay a process until two others have completed. You have already run into Concatenate - this provides a simple way of doing this, as in the following diagram.
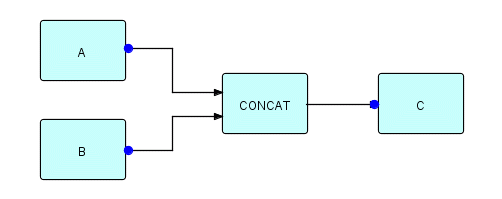
Figure 20.1
In this figure,
processes A and B close their automatic ports when they
terminate. CONCAT will not close down until both A
and B have terminated, so the end of data output by CONCAT
(when it closes down) can be used to delay process C.
Client/server relationships are a good way to solve a particular synchronization problem: suppose you have a stream of transactions that all access the same data base. If you allowed every transaction to run in parallel, and your programs were managing their own data, you would have to provide some kind of enqueue/dequeue mechanism to ensure that different threads were blocked from executing at the same time when this might cause problems. A simpler technique is to make one process a server and only allow that process to access the data base. This is in fact a common type of encapsulation because it allows the server to control what it will accept and when. We described this kind of approach in Chapter 15. The disadvantage of this arrangement, of course, is that you are serializing the data handling part of the transactions, so this may become a bottle-neck, but this is a trade-off that should be the decision of the application designer. It's even better if only a small proportion of the transactions need the server's services, or you have several data bases, each with its own server (like the different stations in a cafeteria, or the tellers in a bank). One other possibility is to use some kind of batch approach, especially in cases where the hit-rate (transactions per data record) is fairly high. After all, batching is just a technique for lowering the per-item cost at the cost of increased start-up and close-down costs. Since a server "batches up" its incoming transactions, you may be able to preprocess them to improve performance.
Another kind of synchronization is built into the "dynamic subnet" mechanism of DFDM. We said before that a composite component monitors the processes within it. In particular, if the composite is substream-sensitive, it handles exactly one substream from every input port on each activation. These input ports are therefore also synchronized, so you can visualize the composite component advancing, one substream at a time, in parallel, across all of its input streams.
Of course, most often such substream-sensitive composite components only have one input port, in which case they process one substream per activation. We have described in some detail how they work in the chapter on Composite Components (Chapter 7). Now we get to use them on something that seems to give programmers a lot of trouble.
Interactive systems and systems which share data bases have to wrestle with the problem of checkpointing. In the old days, checkpointing just meant saving everything about the state of a program, and restart meant loading it all back in and resuming execution. Well, for one thing, a program had to come back to the same location and this might not be available. It became even harder as systems were distributed across multiple tasks or even multiple systems. In FBP, the states of the processes aren't in lock-step any more, so it becomes harder still! In general, as the environment becomes more complex, checkpointing needs more information to be provided by the programmer. However, we would very much like to be able to write a general checkpoint component which we could use across a wide range of applications, and we feel it should be possible with FBP. In the following paragraphs I will describe an approach which seems to fit the requirements. Rather than trying to create an enormously intelligent and complex module, our approach is to provide a series of points in time where as many processes as possible are quiesced, so that they do not require much data to be saved about them.
Consider three scenarios:
a) IMS MPPs take a checkpoint every time they go back to the input queue for another transaction. This "commits" the updates, and unlocks them so other users can access them. If the system crashes before the checkpoint, the updates have logically not been done, and IMS has to ensure that is logically true (even if it has happened physically).
b) a long-running batch application should checkpoint about every half an hour, so that the amount of the job that has to be rerun is never more than half an hour's worth (this applies both to programs updating data bases and to batch jobs using ordinary sequential files).
c) an IMS BMP should checkpoint much more frequently - perhaps as often as every few seconds - as online users of the same data may become hung waiting for the BMP to release data which they need.
The common idea in all these cases is that the system saves the logical state of the system, so that it can be restored if required. The information needed to restore a process to an earlier state is often called its state data. On the other hand, the less data we can get away with saving, the less time checkpoint will take, and the faster any restart can occur if it is needed.
Since checkpointing needs a stable base with as little going on as possible, we will have to quiesce as many of the processes in our application as possible, and have as few IPs in flight between processes as possible. The more we can do this, the less state data we have to save. Here's an analogy: a number of people are swimming in a pool, and a member of the staff decides it's time to put chlorine into it. Since this chemical would be highly irritating to the swimmers, the first thing to do is to get them all out of the water. So the staff member blows the whistle - s/he now has to wait until everyone is out of the water, which might take a little while as everyone has to finish what they are doing. She now puts the chlorine in, waits some amount of time and then blows the whistle again to indicate that it is safe to go back in.
Let's reuse a diagram from Chapter 7:
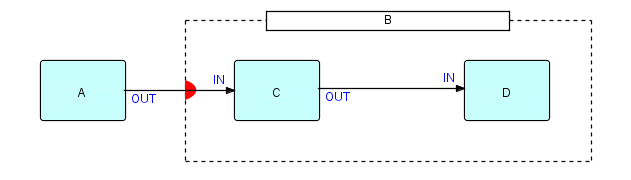
Figure 20.2
This shows a substream-sensitive composite B, containing two
processes C and D. You will remember that, provided the
data coming
from A is grouped into substreams using bracket IPs, the inside
of
B will behave like a little batch job, starting up and closing down for
every
incoming substream. The composite deactivates each time its inside
processes
close down, and it restarts them when the next IP arrives from
outside. During the times when C and D have closed
down, there will
be no IPs in flight, and C and D will not even have any
internal
storage allocated. The composite itself will be inactive. This then
provides
a rather neat mechanism for "getting everyone out of the water",
because,
remember, processes cannot be closed down until they themselves decide
to
allow it.
We have provided a mechanism to clear the swimmers out of the pool, but we also need a way to ensure that they stay out until the chlorine has had time to dissolve! Just provide the composite with a kind of automatic port, which will prevent it from inputting the next substream until a signal arrives. The diagram now looks something like this:
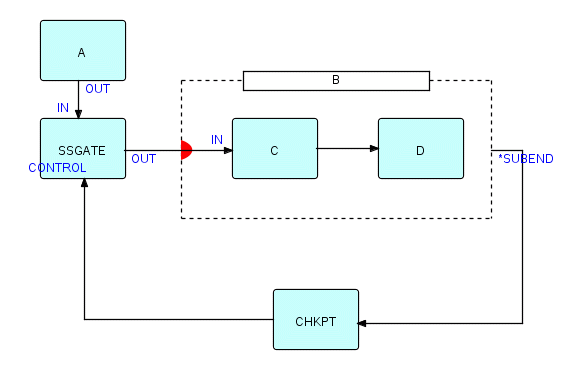
Figure 20.3
In JavaFBP and C#FBP, subnets have an "automatic" port called *SUBEND. When this is connected up, the subnet will send a null packet to the *SUBEND port as soon as all the components within B have terminated. So in this diagram, we connect the subnet's *SUBEND port to CHKPT, which then sends the signal onwards to control a component called SSGATE, to let the subnet know it can accept another substream. SSGATE is a very simple component, and simply releases one substream at a time, each time it receives a signal at its CONTROL port.
There is another idea which is suggested by the swimming-pool analogy: a swimmer who will not get out of the water will hold up the whole process! Remember the term "periodicity", referring to whether a component is a "looper" or a "non-looper" - non-loopers are quiesced between every invocation, so the more often a component gives up control, the more flexible it will be from the point of view of fitting into the checkpoint process.
Since we are using the fact that B's regular (non-automatic) input port is substream-sensitive, we now have to get delimiters into its input stream to make this whole thing work. It may seem strange to use external markers to control what is going on inside the swimming pool, but this is really only a technique for dividing up the incoming stream into well-defined groups - and we want all the processes inside the composite to be able to close down. So what we do is insert delimiters into the incoming stream of IPs at the points where we want checkpoints to occur.
Now, there are two main criteria for when to take checkpoints: amount of I/O and time. Since in IMS a checkpoint will unlock changed records, we want to take checkpoints more frequently if there has been more update activity. Conversely, if the activity is low, we want to take checkpoints occasionally anyway to make sure that other programs are not hung for too long waiting for records to be unlocked. How can we drive checkpoints on both these criteria? Well, a close approximation to the amount of I/O is to count transactions, and do a checkpoint after every 'n' transactions, where 'n' is specifiable from outside. In addition, we want to trigger a checkpoint if 't' seconds or minutes have elapsed without a checkpoint.
Let's do the transaction counting first: we can just have a Count process which inserts a close bracket/open bracket pair every time the count of input IPs reaches a number 'n' (obtained from the option port). This Count process also has to send out an open bracket at the beginning and a close bracket at the end. Schematically:
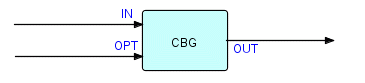
Figure 20.4
We'll call this component CBG for Count-Based Grouping. OPT can specify 'n'; OUT passes on the incoming IPs divided into substreams. So if the input to CBG is
a b c d e f g h i j k l ...
Figure 20.5
and 'n' is set to 5, the output looks like this:
(a b c d e) (f g h i j) (k l ...
Figure 20.6
This also works if the input consists of substreams, rather than just transactions. In general, the count should apply to the highest level substreams (we have seen before that we can treat individual IPs as trivial substreams) - if we were to interrupt a substream to take a checkpoint, we would have a much harder time restarting from where we left off.
But now suppose that, during the "quiet" times, we decide that we also want to insert a bracket pair if 't' seconds or minutes have elapsed without a checkpoint. Let's take a "clock" process referred to at the beginning of the chapter, which generates an IP on every clock tick (specifying the interval via an options port), and merge its output with the input of CBG, as follows:
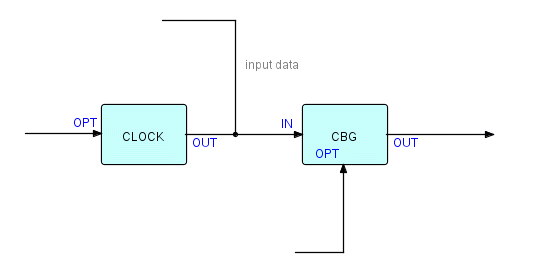
Figure 20.7
where CLOCK generates "clock tick" IPs at regular intervals, which are then merged with the original input IPs on a first come, first served basis. If the original data stream consisted of substreams, we would need a more sophisticated merge process.
The input stream to CBG now looks something like this:
a b c t0 d e f g h i j t1 t2 k l t3 m t4 n o p q r t5 s ...
where tn represents a clock tick
Figure 20.8
Now, the present FBP implementations do not guarantee that these clock ticks will ever get into this data stream unless there are simply no data IPs coming in. This is because we have always concentrated on making sure that all data is processed, but not when. And in fact this is probably adequate in this case, since we only care about the clock ticks when the frequency of incoming data IPs is low. To absolutely guarantee that the data IPs are inserted "in the right place", we would need to implement something called "fair scheduling". I will not describe it here as it is well covered in the related literature.
Clearly when there are fewer data IPs between a pair of clock ticks,
e.g. between t1 and t2, there is less activity; when
there are more IPs, there is more activity. So a simple algorithm might
be to drive a checkpoint (insert back-to-back brackets) on every
incoming clock tick, and also after 'n' IPs following the last clock
tick IP. We might want to fancy this up a bit, by preventing
checkpoints if a previous one occurred within some minimum interval,
but the simple algorithm should do fine for most purposes. A lot of
applications use a time interval only, especially in batch
applications, where the problem is to reduce the cost of reruns, rather
than releasing locked records.
Having identified our "bracket insertion" subnet (Figure 20.7), we can now insert it between A and SSGATE in Figure 20.2, as follows:
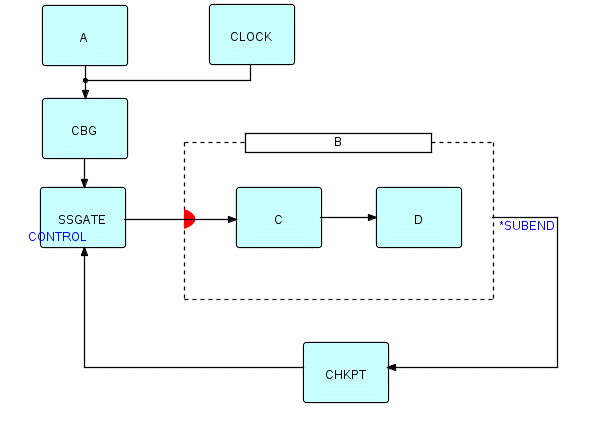
Figure 20.9
We have talked about when to take checkpoints - we now need to discuss what should be saved when we take a checkpoint. Not only does state data have to be saved in case a restart is needed, but in some systems when you take the checkpoint you lose your place - all your fingers get pulled out of the telephone book - so you have to be able to reposition them. So it makes sense to have as few processes active as possible at checkpoint time. In the example shown in Figure 20.3, process A is active at checkpoint time - since it has no input connection, it won't terminate until it has generated all its output IPs. Neither CLOCK, CBG nor CHKPT have any internal state information which needs to be saved if a crash occurs. So this means that A is the only one which needs to be restartable, and there must be a way to make sure that it only generates IPs which have not been processed completely. If A saves state data on a data base or file, the checkpoint mechanism itself will ensure that the state data gets saved when it should, and rolled back when it should. The exception to this is that data IPs which caused errors should probably not get reexecuted, so you may want to store information about them in a non-checkpointable store.
Apart from such oddball cases, we can generalize across the different environments and say that A and processes like it should save their state data on a checkpointable backing store, be able to be restarted using it, and that this whole process should be as automatic as possible. Let's say that the state data has some recognizable empty state - then the state information on the backing store should start off in that empty state, it should be updated for each incoming IP or substream, and the program as a whole should reset the state data to empty when it finishes. This way A can determine if a restart is required and, if so, at what point. Since it is a good idea to separate logic from I/O, we can split A as follows:
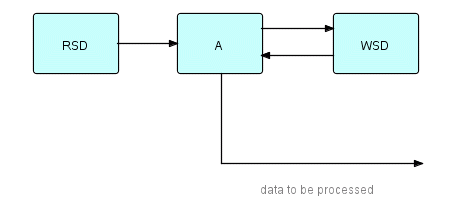
Figure 20.10
In this diagram, A only needs its state data at start time, so we can let RSD (Read State Data) start at beginning of program, and send the data to A. Every time A needs to store its state data, it sends it to WSD (Write State Data). A very often needs to be notified that WSD has stashed it away safely, so we provide a return path for this information.
You may have noticed that A doesn't really need to save its state data until checkpoint time, but it doesn't know when CBG is going to decide a checkpoint is needed - this suggests that we might want to find a way to combine CBG or CHKPT with A's writing to backing store. The other thing we might do is have a general repository of state data, and let A request it, say, by providing its process name as a key. A solution which combines all these ideas is to use a process like the List Manager (described in the next chapter) to hold up-to-date state data in high speed memory, and then expand the function of CHKPT so it writes out this information to disk before requesting the checkpoint. We therefore replace WSD by a State Data Repository (call it SDR ). CHKPT has to request the state data from SDR, so there will be connections in both directions between these two processes. The final diagram might therefore look something like the following figure:
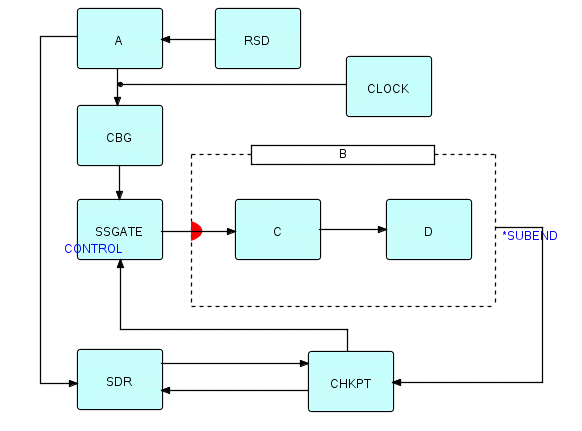
Figure 20.11
where there are two connections between SDR and CHKPT, one in each direction. The connection from CHKPT to SDR is used to allow CHKPT to request its stored data; the reverse connection is for SDR to send the requested data.
This is just a sketch, and even at that it's starting to look a bit complicated, but most of the components can be off the shelf, so they won't have to programmed from scratch for every application. At this point, I'm sure you can all come up with better solutions which draw on your own expertise - the point is to design generalized utility components which encapsulate expertise, but which still are easy for other, less expert programmers to use. When you consider the potential cost of reruns to your shop, I'm sure you can see that some standard, easy to use, checkpointing approaches and components will be well worth the effort that goes into developing them and I have tried to show that FBP's powerful modularization capabilities will make that job much easier.