This chapter has been excerpted from the book "Flow-Based Programming: A New Approach to Application Development" (van Nostrand Reinhold, 1994), by J.Paul Morrison. A second edition (2010) is now available from CreateSpace eStore and Amazon.com. The 2nd edition is also available in e-book format from Kindle (Kindle format) and Lulu (epub format). To find out more about FBP, click on FBP.
For definitions of FBP terms, see Glossary.
|
Material from book starts here:
In Chapter 3 (Concepts), we talked about hierarchic structures of substreams - there is obviously another type of hierarchic structure in FBP, which has been alluded to earlier: the hierarchical relationship between components. Although the processes in an FBP application are all little main lines, cooperating at the same level to perform a job of work, it is easier to build the total structure hierarchically, with a "top" structure comprising two or more processes, most of which will be implemented using composite components. Each composite component in turn "explodes" into two or more processes, and so on, until you reach a level where you can take advantage of existing components, or you decide that you are going to write your own elementary components, rather than continuing the explosion process. Apart from the emphasis on using preexisting components, this is essentially the stepwise decomposition methodology of Structured Analysis.
The application of this approach to FBP is largely due to the late Wayne Stevens, arising from his work on Structured Programming and application development methodologies in general. From a hierarchy point of view, a running program built using AMPS (the first FBP dialect) was "flat" - it had no hierarchic structure at all. People drew application networks on big sheets of drawing paper, and stuck them up on their cubicle walls. These drawings would then gradually accumulate an overlay of comments and remarks as the developers added descriptions of data streams, parametrization, DDnames, etc. When the time came to implement the networks, the developer simply converted the drawing into a list of macro calls.
Wayne realized that a better way to develop these networks was to use the decomposition techniques of Structured Analysis, but that, unlike conventional programming, there was no change in viewpoint as you moved from design to implementation. In conventional program development there is a "gap" between the data flow approach used during design and the control flow viewpoint required during programming, which is extraordinarily difficult to get across. When building DFDM we therefore provided a way for developers to grow their systems by stepwise decomposition, but at structure build time the hierarchy got "flattened" into the conventional AMPS-type network. This approach turned out to be very successful - I alluded earlier to a colleague who built a 200-node network without once drawing a picture of a network!
So DFDM networks can be built up hierarchically, but are flat at run-time. This approach lets developers build up their applications layer by layer. As we have shown in some of the examples, you could also take a simple component and replace it by a subnet - this gives an additional dimension of expandability. In DFDM we have seen that subnets can be stored on reusable libraries and reused. However, they must be stored in interpretable form, so their internal structure is visible (although they are built out of black boxes). It would be even better for someone marketing an application to be able to store some or all of an application as "black box" subnets, so that the customer cannot see inside the subnets. Remember that DFDM has the ability to take an interpretable network and convert it into a directly executable load module. It should be possible to do this with a subnet as well, so that a part of an application is held as a black box as well. The original motivation for doing this, however, was performance of interactive systems.
Consider an application comprising 200 processes - when you link all the code together into a single module, the result is a pretty big load module. The particular application mentioned above ran under IMS/DC, and the network was executed once for each transaction. However, when we started measuring performance, we found that, on each pass through the network, even though IMS loads in the whole network for most transactions, only about 1/3 of the processes actually got executed for a given transaction. We wondered if we could just build a framework for an interactive application and load in the required chunks of logic dynamically. This would have the advantage that it would take less time to load in the application on each transaction, because the individual load modules would be smaller, thus improving response time. Also, on each transaction you would only need the framework and the particular dynamic chunk involved, so the framework could actually be made resident, improving response time even more. It should also make it easier to expand the application and even change it on the fly. The problem was: how do you run a network which modifies itself dynamically without losing track of your data?
For a long time, I resisted this idea as I had a vision of a complex subway system like the London underground, but with the added complexity that stations would be appearing and disappearing at random. How would it feel to be a passenger in such a system?! I had experimented with loading in individual components dynamically under AMPS: I was able to read in or load a piece of code, treating it as pure data, and let it travel through a network, until it arrived at a "blank" process (one which was connected to other processes but had no code assigned to it - a sort of "tabula rasa" process), at which point it would get executed, so I felt that dynamic process modification could work under controlled circumstances. Wayne Stevens had also proposed a particular case of dynamic network modification which is simpler than what we eventually landed up with, but we never got around to trying it out: his image was of engineers repairing a dam. The water has to keep flowing, so the engineers divert the water through a secondary channel. After the dam has been repaired, the water flow can be restored to its original channel. This seems like it would be a good way to do maintenance on an FBP system which has to keep running 24 hours a day, like a banking system.
I myself came up with a different and somewhat more complicated approach, which however was also safe and manageable, and which also solved the problem of load module size I described above. The trick I discovered was to have a "mother" process load a subnet (in compiled and linkedited form), start up the processes in the subnet, and then go to sleep until all of her "daughter" processes had terminated. At subnet start time, the daughters are counted, so the subnet is finished when the count of active daughters has gone down to zero. While the mother is sleeping, some of the daughter processes can be given control of their mother's input and output ports. There will be no conflict over who has control of the ports, as the mother and the daughters are never awake at the same time.
We called these subnets in DFDM dynamic subnets. The "mother" was a generalized component called the Subnet Manager, which continuously iterated through the following logic:
-
receive the name of a subnet in an IP,
-
load the subnet load module,
-
"stitch" it into the main network,
-
start it up and go to sleep,
-
wake up when all the daughter processes have terminated,
-
dispose of the subnet load module and repeat these steps
In addition to the Subnet Manager, we added special precoded components (Subnet In and Subnet Out) which were used for input and output handling by the subnet. Here is a picture of a very simple dynamic subnet (with one input data port and one output port):
Figure 7.1
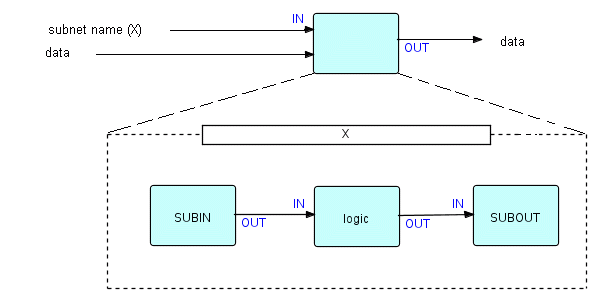
When 'X' is given control, it behaves just like a mini-application: technically SUBIN has no input ports, so it gets initiated. The other two processes have input ports, so they will not be initiated until data arrives. SUBIN and SUBOUT have the ability to use their mother's input and output ports respectively. They have to be separate processes as they have to be independently suspendable. Thus, if mother had two input data ports, the subnet would have to have two SUBIN processes to handle them.
Now we noticed a strange thing: normally, once a process terminates, it can never be started again. We saw that the Subnet Manager had to have the unique ability of being able to restart terminated processes. This was the only function in DFDM which had this ability, and it was in a very special off-the-shelf component.
In the work which followed DFDM (referred to above under the name FPE), we realized that these characteristics of dynamic subnets could be extended to static networks as well. We moved this ability into the infrastructure (removing the subnet names port), so that all subnets had a built-in monitoring process. This approach naturally coordinated the hierarchy of processes with the stream hierarchy. In addition, since the monitoring process's other job is to stitch the composite into the main network, we could now have "black box" composite components. This facility would allow subnets to be packaged as separate load modules for distribution, which could later be linked with other components by a developer to form the full application network. This seems very attractive, as a software manufacturer will be able to sell a composite component without having to reveal its internals (as would be required by DFDM)! We will also see later (in Chapter 20) that these concepts give us an intuitively straight-forward way of implementing fairly complex situations such as checkpointing long-running applications.
We mentioned above how, in dynamic subnets, we have a "mother" process which monitors the execution of its daughter processes, and can "revive" them after they have all closed down. However, since the subnet cannot close down until all IPs have been received at all input ports, what would be the point of ever waking up the subnet again? Well, if that was all we could do, it would just be a performance improvement. However, we came up with an idea which we thought dovetailed in pretty neatly. Why not put markers in the data stream, such that the internal subnet thinks it is seeing end of data, and will terminate, but in fact there is more data to come, so it will be revived? We did this by adding an option to composite components called substream sensitivity. This was implemented in DFDM for dynamic subnets, and in FPE as an option on all composite components. Substream-sensitive composites essentially keep track of the bracket nesting levels at each of their input ports, and whenever this level drops to zero for a given port, the port involved is closed, resulting in an "end of data" indication next time the daughter process does a receive from that port. Essentially they make substreams on the outside look like streams on the inside. Since you can nest subnets within subnets, each level of nesting strips off one level of bracketing (call it "the application onion").
Let us start with one input data port only. Suppose we have a "substream-sensitive" composite B, which contains C and D, as follows:
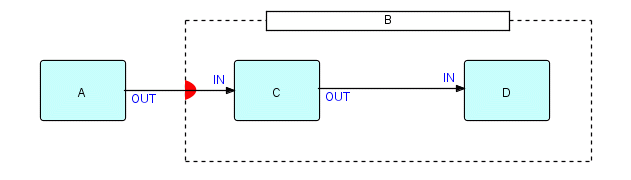
The point shown with a solid semicircle is a substream-sensitive port on B. [This is sort of a shorthand - the solid semicircle will be implemented as an "external port", which has no real input ports, but can access the input port of the subnet.]
Figure 7.2
Suppose that A generates a stream as follows:
(a b c d e f) (g h i) (j k l m)...
reading from left to right. Then C is going to see IPs a, b, c, d, e and f, and then end of data. At end of data it terminates, as it has no upstream processes at the same level within its enclosing composite, enabling D to terminate also. If D was a Writer, it would then close the file it was writing to. However, we know (although the subnet doesn't) that C and D are not permanently "dead" - when the next open bracket arrives at B's input port, they will both be revived. As far as C and D are concerned, IPs a through f constitute a complete "application", but, as far as B is concerned, each substream, e.g. a through f results in a single activation of the internal subnet.
What happened to the brackets? Well, we could add a process to remove the enclosing brackets of a substream, but it seemed a good idea to add the ability to substream-sensitive ports to drop the brackets if the designer wants. However, you may not always want this: for instance, if D was outputting IPs to B's output port, you might have to be able to put the brackets back on again.
In this example, you can see the insides of a composite working like a complete application within each activation of a composite. The power of this concept is that you can match levels of composite component to levels of nesting of substreams. So, substream structure can be related to subnet structure. I would like to record here the fact that this very powerful idea came from Herman van Goolen, of IBM Netherlands, and I feel it is very elegant. You can probably now see why we use brackets both to delimit substreams and as the delimiters which substream-sensitive composites respond to.
If we have more than one input port on a substream-sensitive composite component, as described above, our composite will process one substream from each input port successively until all the input ports are exhausted. Processing of these input streams will therefore be synchronized at the substream level. Other kinds of synchronization are also possible, of course, but we have found this type to be the most generally useful. It also ties in nicely with the requirements of Checkpointing (see Chapter 20).