This chapter has been excerpted from the book "Flow-Based Programming: A New Approach to Application Development" (van Nostrand Reinhold, 1994), by J.Paul Morrison. A second edition (2010) is now available from CreateSpace eStore and Amazon.com. The 2nd edition is also available in e-book format from Kindle (Kindle format) and Lulu (epub format). To find out more about FBP, click on FBP.
For definitions of FBP terms, see Glossary.
|
Material from book starts here:
"A complex system which works is invariably found to have evolved from a simple system which works", John Gall (1978)
"Systems run better when designed to run downhill. Corollary: Systems aligned with human motivational vectors will sometimes work. Systems opposing such vectors work poorly or not at all", John Gall (1978)
"Loose systems last longer and work better", John Gall (1978)
A colleague of mine, Dave Olson, has been studying the application development process in particular, and large organizations in general, and has realized that the budding science of chaos has a lot to tell us about what is going on in this kind of complex process and what we can do about it. In the study of chaos one frequently runs into feedback loops, and, in our business, just as one example, we have all experienced what happens when a project starts to run late. Fred Brooks described this kind of thing in his celebrated book, "The Mythical Man-Month" (1975). Chaotic systems also are characterized by areas of order and areas of apparent disorder. Dave's recent book describes these concepts and also describes how they can be applied to explain and handle many of the problems we run into in our business (Olson 1993). In a section on techniques for reducing disorder, he talks about DFDM and its relationship to the Jackson Inversion methodology (mentioned elsewhere in this book). He later gives more detail on DFDM, and describes how you would approach designing an application with it as follows:
To use DFDM, you first define the data requirements of the application, defining how the data flows and is transformed during the application process. Then you create transform modules for the places in the flow where data must be merged, split, transformed or reported. The full application definition consists of the data definitions and data flows, defined to DFDM, and the transform modules that are invoked by the platform.
In a personal communication to me, he expands this into the following set of recommendations:
-
View the application in terms of the information that needs to move from place to place.
-
Create transform modules for the places where data must be merged, split, transformed, or reported.
-
Separate data definitions from transform code so that transforms can be reusable code. Transforms thus care more about what has to be done, not so much about how individual pieces of information are represented.
-
Provide certain building block transforms that will be needed by most applications, including file storage, file retrieval, file copy, printing, user interaction, etc.
-
Build a systems framework so that an application can be defined in terms of its data flows and transforms; the framework handles scheduling, concurrency, and data transfers between transforms.
Doesn't sound much like conventional programming, does it? However, viewing an application in terms of data and the transforms which apply to it underlies many design methodologies. The problem has always been how to get from such a design to a working program. This is the "gap" I have referred to above. With FBP, you can move down from the highest level design all the way to running code, without having to change your viewpoint.
The first stage of designing an application is to lay out our processes and the flows between them. This is pretty standard Structured Analysis, and has been written about extensively by Wayne Stevens and others. Of course the scope of your application is sometimes not obvious - we can draw our network of processes as large or as small as we want. A system is whatever you draw a dotted line around. By this I mean that the boundary of any system is determined by an arbitrary decision that, for practical purposes, part of the world is going to be considered and part is going to be ignored. In the astronomy of our Solar system, we can treat influences from outside the Solar system as effectively negligible, and this works fine most of the time, even though theoretically every object in the universe affects every other. You may think that your skin separates a well-defined "you" from the rest of the universe, but biochemistry teaches us that all sorts of molecules are constantly passing in and out through this apparent barrier. Indeed all the molecules in our bodies are totally replaced over a period of a few years. This is rather a Zen idea - taken to the extreme it says that objects don't have an objective existence (pun intended), but are just the way we "chunk" the universe. And we should also be aware of the way the words we use affect the way we view the universe. As a linguist, I find a number of B.L. Whorf's examples quite striking: in one example (Whorf 1956), he gives a word in one of the Amerindian languages that describes people travelling in a canoe, in which there is no identifiable root meaning "canoe". The canoe is so much an assumed part of their experience that it doesn't have to be named explicitly.
Thus, to design systems, we have to delineate the system we are going to design. This first decision is critical, and may not be all that obvious. So consider the context of the system you are designing: have well-defined (and not too many) interfaces with the systems outside your chosen system.
You can now lay out the processes and flows of your system. Explode the processes progressively until you get down to the level where you start to make use of preexisting components. In FBP, you will find these starting to affect your design as you get closer to them. This is one of the points where FBP design differs from conventional programming, but it should not really surprise us as we do not design bridges or houses purely top-down or purely bottom-up. As I said before, how can you "decompose" the design for a house so that it results in the invention of dry-wall? But conversely, you have to know where you're going in order to be able to determine whether you're getting closer to it. Ends and means must converge. Design is a self-conscious process of using existing materials and ideas or inventing new ones, to achieve a desired goal.
On the way to your goal, like any hiker, you have to be willing and able to change your plans as you go. The nice thing about programming is that you can move between a "real" program and its simulation very easily, so you can try something and modify it until you're happy with it. In fact, with FBP we can realize an old programming dream of being able to grow an application from its simulation. You can replace processes by components which just use up 'x' seconds of time, and vice versa.
In programming I believe there should be no strong distinction between a prototype and a real program until the real program actually goes into production. If something in the environment or in your understanding changes, so that an old assumption is no longer true, you have to be able to change your design. While I am very aware that the cost of change goes up the further back you go in the development process, you have to know when to cut your losses, and go back and do some redesign. If it helps, consider how much harder it is for, say, a surgeon to do this!
If you combine FBP with iterative development, I believe that you have a very powerful and responsive application development technology. You can try different approaches, it's cheap to make changes, and when it is time to dot the i's and cross the t's, it is essentially a linear process. By way of comparison, I believe that the chief failing of the "waterfall" methodology was that it was so awkward to go back that development teams would press forward phase after phase, getting deeper and deeper into the swamp as they went, or they would redesign, and pretend they were doing development (or even testing!). Here is Dave Olson again: "Programmers know that highly detailed linear development processes don't match the way real programming is done, but plans and schedules are laid out using the idea, anyway." He goes on to stress that, while there are some projects for which the "waterfall" process will work fine, you cannot and should not shoehorn every project into it.
Apart from the iterative explosion process for networks we have just described (vertical), in FBP I have found there is another process which is orthogonal to it. This is the process of cutting up networks horizontally, to decide how and where they are going to run. In this process, we assign parts of our network to different "engines" or environments. Since FBP systems are designed in terms of communicating processes, these processes can run on all sorts of different machines or platforms - in fact anywhere that has a communication facility.
When you think about the ways a flow can be chopped up, remember you can use anything that communicates by means of data, which in data processing means practically any piece of hardware or software. I call this process "cleaving". Networks can be cleft (or cloven) in any of the following ways (in no particular order and not at all mutually exclusive):
-
multiple computers (hosts, mid-range, PCs or mixture)
-
multiple processors within one computer
-
multiple tasks
-
different geographical sites
-
multiple job steps within a job
-
secondary transactions
-
client/server
-
multiple virtual machines
-
etc.
All of these have their design considerations, but that's just like the real world, where there are many different processes and they all communicate in different ways. Today I can call up a friend by phone, mail him or her a hand-written letter, fax it, communicate by E-mail, send a telegram, or stick a note in a bottle, throw it into the Atlantic and hope it gets delivered eventually! Each one of these has areas where it is stronger or weaker.
Let us take as our starting point one of the most common network cleaving techniques: multiple job steps in a job. Suppose you have decided that your network is going to run as a batch job under MVS. Here is a picture of a simple network:

Figure 15.1
Let us suppose that, for whatever reason, we want to run this as multiple job steps of a single batch job. Now we know that job steps can only run sequentially. While they can be skipped, they cannot be repeated. This means that B and C must be in the same job step. However A and D can be split off into different job steps if desired. Suppose we decide to make both A and D separate job steps - this will result in 3 job steps, in total.
We also know how job steps communicate - by data files (yet another kind of data flow). In FBP we are free to replace any connection with a sequential file, so we can change the connections leading out of A and those leading into D to files. Once we separate two processes into different job steps, of course all connections between them must be replaced by files. Each one of these will in turn require a Writer and Reader. Using dotted lines to show step boundaries and [X]'s to indicate files, our diagram now looks like this:

Figure 15.2
I have shown the Writers and Readers around the files as W's and R's to keep the similarity between the two previous figures. These are proper processes even though they are not shown as boxes. Steps 1 and 3 thus have 3 processes each; step 2 has 4.
If we show this picture at the job step level, we see that we could have designed it this way earlier in the process, and then exploded it to get the previous figure.
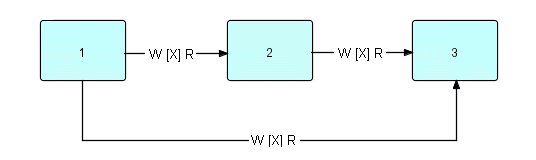
Figure 15.3
However, it is much better to design a complete application and then cleave it later, as other considerations may affect our decisions on how the network should be split up. (For instance, the problem I mentioned in an earlier chapter of not being able to overlap sorts forced many of them into separate job steps!) In fact, since it is so easy to move processes from one job step to another, there is no particular point in splitting up our network early - you can just as well leave it to the last minute. In conventional programming, moving logic from one job step to another is very difficult, due to the drastic change of viewpoint when you move from data flow design to control flow implementation, so the decision about what are going to be the job steps has to be made very early, and tends to affect the whole implementation process from that point on.
I'd like to make another point about this rather simple example: in Figure 15.2, you notice that communication between process A and process B is managed by two processes and a file. In FBP, this is a common pattern whenever any two processes communicate other than via FBP connections. Thus a communication line might be "managed" by a VTAM Send process at one end, and a VTAM Receive process at the other. I will give a few examples later in this chapter of other kinds of communication between networks, and you will see this pattern in all of them.
A more subtle point is that the transition from Figure 15.1 to Figure 15.2 was made entirely by manipulating the network, without having to add any complexity to the underlying software. This point is related to the principle of open architectures I talked about in an earlier chapter: our experience is that it is much better to implement subsystems like file handling and communications as visible processes under the developer's control than to bury them in the software infrastructure. Since the latter is common practice among software developers, all I can say is that this preference is based on solid experience. But consider the advantages: Write-file-Read becomes just one mechanism supporting a particular way of cleaving networks - we could have used many others, and in fact could change from one to another during project development.
To try to show what happens if we go the other way, consider what would have happened if we had decided to have two kinds of connections: an intra-step connection and an inter-step connection. Let's take Figure 15.1 and assign each connection to one of these two categories depending on whether it crosses a step boundary or not (we'll assume you do this at the same time you divide the network up into job steps).

Figure 15.4
Now, I claim that we have made both the implementation and the mental model more complex, without providing any more function to the developer. Not only will the added complexity make the system harder to visualize and therefore harder to trouble-shoot, but we may have made some useful operating system features inaccessible or only accessible through still more complexity in the interface. And if a programmer wants to replace the inter-step connections with, say, a DB2 data base, s/he is going to have to add extra processes anyway, and change the inter-step connections back to intra-step connections....
Another way of presenting this discussion is that it is very important, when designing software, to decide on its scope. The scope of a given software system obviously depends on the particular environment it is running in, but it is sometimes not obvious which of the various constructs of that environment should be the basic "unit" of your software. In the case of DFDM, it will probably be obvious from all the foregoing descriptions and examples that a DFDM network corresponds to one of the following:
-
an MVS job step,
-
an IMS transaction,
-
BMP,
-
batch job,
-
a CMS "program"
However, in the early stages of DFDM it was not at all obvious that this was the right decision. Even the CMS statement above is somewhat vague because the word "program" is one of the most confusing in the whole science of "programming"! Consider Figure 15.4 above - if we had implemented DFDM that way, the scope of a DFDM application would have been an MVS job, not a job step. There is no counterpart of this in IMS (except perhaps a "conversation"), or in CMS, so it would have been harder for programmers to move from one of these environments to another. I have always considered our choice of the scope of a network as being one of the keys to the usability of DFDM. In THREADS, a network is implemented as an .EXE file, which I think is also usually referred to as a "program".
So a system should have components of well-defined scope, with visible, controllable interfaces between them - in fact very much like FBP itself! Such systems (and, I believe, only such systems) can then be combined easily in open architectures.
Let's take another look at Figure 15.2. We could draw a box around each of the patterns shown as
----W [X] R----
to make it a process in its own right. This process can run perfectly well within a job step, and in fact we have met this pattern before in Chapter 13 (Scheduling Rules), where we drew it like this:
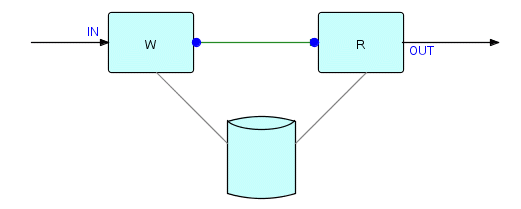
Figure 15.5
As you will recollect, we used automatic ports to ensure that the reader did not start until the writer had finished writing the file. Taken as a whole, this process is rather like a sort without the sorting function! It writes a whole data stream out to disk, then reads it back and sends it on. We can also state this a bit differently: it keeps accepting IPs, storing them in arrival sequence, until it detects end of data; it then retrieves them and sends them on. This suggests the other name for this structure - we shall run into it again in the chapter on Deadlocks, where it is called, slightly fancifully, an "infinite queue". You will find that it is one of the most useful techniques for preventing deadlocks.
Why did we call it an "infinite queue"? a) In the old days we used to call "connections" "queues". b) Using a file for this type of structure gives us an effectively infinite capacity because, while a connection has whatever capacity the developer specified (or the default if none was specified), the pattern shown in Figure 15.6 can keep on soaking up IPs until it hits the maximum number of records allowed by the operating system or storage device. Actually, we could increase its capacity still further by using smart code inside a special-purpose component.
Given that processes are connected by queues, how can a particular type of process also be called a "queue"? We suggested at the beginning of the chapter that processes can be as large or small as you like. For pragmatic purposes, we have chosen to pick a certain "grain" of process as the one we will implement, and connect them with a different mechanism, the connection. There are higher-level processes, which we call subnets, and the highest subnets are job steps. Above this are still higher processes called jobs, applications, and so on. Different levels of this hierarchy will tend to be implemented by different mechanisms, but, if we need to, we can always move processes up or down the hierarchy. Treating a connection as a special type of process is like using a magnifying glass to zoom in on a part of our network. Any time we want a connection to behave differently from normal connections, we simply replace it by a process (plus the connections on either end). We could also use this technique if we wanted to have another type of connection between processes, say, a connection supporting "priority mail". However this will require additional port names - a number of writers have described processes implementing FBP's connections (also known as "bounded buffers"), but we have found it more convenient to put them in the infrastructure.
As I read the ever-growing body of literature on parallel processes, I have been struck by the variation in granularity across the various implementations, from fine-grained to very coarse-grained. And in fact you will have noticed that FBP processes vary from very simple to quite complex. However, they do seem to agree on a certain "grain size". In the chapter on performance, we will talk about how granularity affects performance, and how this fact can be used to obtain trade-offs between maintainability and performance.
In addition, we do not claim that the level of granularity described in this book is the best or the final one for all purposes - only that it is a level which we have found to provide a good balance between performance and expressive power. It is productive of useful components and developers seem to be able to become comfortable with it! Here is a network which implements what used to be called a "half adder", using IPs to represent bits and FBP processes to model Boolean operations - while this worked fine as a simulation, I do not suggest that we could build a real machine on it (although we might be able to build a slow simulation of a machine)!

Figure 15.6
where RPL means Replicate, AND is the Boolean AND operator, and XOR is the Boolean exclusive OR.
We alluded above to "managing" a communication line by means of matching VTAM processes. Here we could distribute a network of processes between multiple computers, which may or may not be in the same room, building, city or country. This is "distributed" processing, which is gaining more and more attention. Instead of each computer labouring away by itself in splendid isolation, people today are accustomed to having computers be able to talk to each other around the world, using a wide variety of different communication techniques. The Net (Cyberspace) of today was foreshadowed within the IBM Corporation by the internal network called VNET, which is an incredibly powerful medium for sharing information and ideas. I once impressed the heck out of a visitor by showing him how, from a terminal in Toronto, by using a one-line command, one could display the VNET file traffic between Australia and Japan!
While I am not an expert in distributed systems, it seems logical to me that if we have two computers, each with multiple processes running on it, communicating asynchronously, then the two computers should be able to exchange data by simply using two dedicated processes at each end of the link. Schematically:

Figure 15.7
This diagram shows two systems, each with a Sender and a Receiver process. The Sender of one system sends to the Receiver of the other, and vice versa. At the far left and far right of the diagram there will be more processes, which are implementing the applications on each computer. You could view this whole structure as a single loop-type network which has been distributed over two systems [the fixed capacity of FBP connections can be simulated, we believe, by having R and S send and wait for acknowledgment packets, respectively, after every 'n' packets].
Clearly, in this example, we have coupled our two systems together, so that the speeds of the two systems are effectively matched. However, if the traffic between the systems is low enough, this may not be a bad design for some scenarios. For example, suppose a bank decides to spread its processing over two or more machines in different regions, linked by communication lines. Banking transactions are usually characterized by high "locality". The largest proportion of banking transactions will be on the customer's branch, a smaller number will be between branches on the same regional computer (assuming the bank splits up its branches that way), and only what's left over will actually need to travel between different regional machines, and most of the time this traffic should be balanced in the two directions. So we can visualize each machine as a "cloud" of processes, and every so often a transaction gets sent across to the other machine. If response time is adequate and/or the traffic is low enough, the requesting process can actually wait until a response comes back. If this is not adequate, the requesting process must have some way of suspending the logic which needs the data, and then resuming it later. This is exactly the problem of suspending/resuming FBP processes, but at a higher level. Also, in the case of links, there is the possibility that the link has gone down (when there is a physical medium like wire, it can be cut or struck by lightning), so some thought has to go into what kind of degraded performance the application should provide if one of the systems cannot communicate with another.
One topic which comes up a lot with distributed systems is the vexed question of how to synchronize events across multiple systems. If all of the processes in an IMS application are running in the same IMS region, then issuing one Rollback command will undo all data base changes since the last checkpoint, so it is easy enough to undo some data base updates if it turns out that the larger action they are part of has failed. Now, however, imagine that we want to transfer funds between two different hardware nodes - you have to withdraw funds from an account on one node and deposit them into an account on the other one. Either of these operations can go wrong, so you need some hand-shaking to either delay both until you know it's safe, or be prepared to undo an earlier operation if a later one goes awry. The latter approach seems more natural, even if less general: you do the withdrawal first; if that works, you send an IP representing a sum of money to the other node, specifying both source and destination accounts. If the receiving end for some reason cannot accept the transfer, it gets sent back to be redeposited. You might call this the "optimistic" stategy, while only committing when you know both ends are OK is the "pessimistic" strategy. The point is that qualitative changes occur when you split your network between systems, but this is an area of expertise in its own right, and the argument for distributing systems is so compelling that the new problems that it raises will definitely be solved! After all, systems of communicating humans have been working this way since time immemorial! IBM has recently announced its Message and Queuing Interface, so it is betting that asynchronous communication between systems is the way to go, and I am sure there will be solutions to these problems appearing over the next few years.
There is a lot of interest these days in what are called client-server relationships. You may in fact have realized by now that, in FBP, every process is a server to its upstream processes. In the banking example above, where there are more than two systems involved, every system is potentially a server to all the others. So the client-server paradigm is a very general one, from the level of FBP processes as high up as you care to go. However, it is important to stress also that FBP processes are peers, and peer-to-peer, which is more general than client-server, is a very natural match with the FBP approach. The FBP model is cooperative rather than hierarchical.
One major addition we have to make to the above schema is to allow for the possibility of asynchronous flows from multiple sources. If the Toronto machine can have data flowing in from Montreal and/or Edmonton, it has to be able to accept data on a first-come, first-served basis (subject, perhaps, to a priority scheme if there is a need to handle express messages). We have already seen in FBP a mechanism which provides this - namely, multiple output ports feeding one input port. If you have this situation, you must have some way of routing the response back to the right source, so the data must be tagged in some way. In FBP, one way is to arrange for the incoming data to contain a "source index", which we could use as an output port element number. Showing just two clients, schematically:

Figure 15.8
In this configuration "S.0" sends an IP to the server, and then waits for the response to arrive back, after which it can send another request. Meanwhile, "S.1" is going through the same cycle. You can see from the diagram that IPs from "S.0" and "S.1" will arrive at the server in "first come, first served" sequence. Of course, the server can only handle one request at a time, so it has to be able to process requests as fast as possible, relative to the arrival rate. Otherwise, a queue builds up which will in turn slow down all the processes requesting service. As in the above discussion of "cleaving" networks, any line in the above diagram can be replaced by other forms of communication, including the above-mentioned "Send-line-Receive" pattern, resulting in various kinds of distributed network. The "n to one" connection in the middle of Figure 15.9 would be implemented very naturally as multiple Senders sending to a single Receiver process. In FBP, the reverse situation, a "one to n" connection, is not implemented directly in network notation, but can be implemented simply by a Replicate process. In a distributed network, this would correspond naturally to a "broadcast" communication function, where one process sends the same message to multiple receivers. This is the kind of arrangement used by many taxi dispatching systems, where the dispatcher sends in broadcast mode, but individual taxis reply on their own wavelength.
We mentioned that the server in Figure 15.9 can only handle one request at a time. This would be the simplest way of implementing its logic. Another wrinkle might be to add an "express" port, like the express lane at some banks. However, unless the express port has its own server, this scheme can still be degraded by a low-priority request which is tying up the server. So it might be better to have two processes running concurrently, one handling express requests, and the other low--priority requests. Of course, this adds logical complexity, especially if the two servers are competing for resources. One possible solution is to implement an enqueue/dequeue mechanism to resolve such conflicts - this actually fits quite well with FBP, and was implemented experimentally in DFDM. The above-mentioned article (Suzuki et al. 1985) also describes a similar feature its authors developed as an alternative communication mechanism between processes.
Generalizing still further, we may multiplex the server by having multiple instances of the same component. For instance, suppose the server is doing I/O which may be overlapped with processing - you could have many instances of the same component serving the client queue. This is like many bank branches today, where several tellers are servicing a single queue of customers. To allow them to overlap I/O, you have to be able to suspend only a single process on an event, without hanging the whole application. DFDM supported this for the MVS "basic" access methods (BSAM, BPAM, BDAM), VSAM and EXCP. THREADS does not support this. Of course, this is subject to the same resource contention we talked about above.
If you are going to multiplex your server processes, you will probably need a "load balancing" process to ensure that queues don't build up more in front of some servers than others. The resulting diagram might therefore look like this:

Figure 15.9
In the above diagram, requests are assumed to be coming in at the left side, tagged with an indication as to their source. They merge into LB which performs load balancing, sending the incoming requests to whichever server has the shortest input queue (number of IPs in its input connection). From the servers, the IPs then travel to RF, which is a redistribution facility. From there they eventually travel back to their original requesting processes. You will find a description in Chapter 22 of how this technique was used very effectively to reduce the run-time for a disk scanning program from 2 hours down to 20 minutes.
One topic which has been getting a lot of attention recently is that of portability of code. This is certainly one of the appeals of HLLs, but my personal feeling is that their disadvantages outweigh their advantages. But clearly you cannot port Assembler language from one type of hardware to another using a different instruction set. I believe the solution is to port at the function level. A Collator can be defined to do the same job on two or more input streams, independent of what language it was coded in. So we can move Collators from one machine to another and expect that our function works identically. Not only does this approach take advantage of the strength of the black box concept, but it removes the necessity for code to be white boxes written in a portable language (which usually results in lowest-common-denominator languages, or frustrating and time-consuming negotiation about standards).
We have now seen how to decompose designs vertically, cleave them horizontally, and some other concepts such as client-server relationships. But in what order should you develop your application? I don't think there is a fixed sequence, but I have found two sequences productive: along the lines of bottom-up and top-down, I call them "output-backwards" and "centre-out". "Output-backwards" means that you start with the outputs intended for human consumption, and work backwards deciding how this data is going to be generated. If it's an interactive application, output is the screen, and you will eventually work back to the screen, which closes the loop. "Centre-out" means that you start with the core processes, usually the ones which do business logic, together with any required Collators and Splitters, and get them working using the simplest Reader and Display components. Fancy output formatting, input editing, etc., can then be added incrementally working out from the centre. This approach is really a kind of prototyping, as you can develop the main logic and check it out first, before investing effort in making the output pretty, making the application more robust, etc. At selected points along the way, you can demonstrate the system to potential customers, prospective users, your manager, or whomever.
Last but not least, during this whole process of development you will want to test your developing product. You can test any component by just feeding it what it needs for input and watching what comes out as output. You generate its input using Readers and its output using some kind of Display component. In the early stages, the simpler these scaffolding components are, the better. The trick, as in prototyping, is to only introduce one unknown at a time. The more you can use precoded components, and the simpler they are, the less unknowns you will be dealing with. Any time you want to see the data that is travelling across a connection, just insert a Display process, like a probe in an electrical circuit. So testing is very simple.
As I have tried to emphasize in what went before, I feel that, while FBP is great for developing applications, it is perhaps even more effective in improving maintainability. After all, all attempts to make programs more maintainable after the fact have failed, so maintainability has to be designed in from the start. As some of the anecdotes above attest, FBP seems to have it designed into its very fabric. Given that your program will change constantly over the years, you will need a simple way to verify that the logic which you didn't change still works. Testing that a system still behaves the way it used to is often called "regression testing". Wayne Stevens came up with an FBP-based technique for doing this. You take the original output of the system to be tested and store it in a file; you then imbed your system in a network like this:
where
SS represents the Subject System
R is a Reader for the previously stored output
C compares the stored output against current output
RPT generates a report on the differences

Figure 15.10
This network is clear while also being generic. For instance, you might need to insert filters on C's two input streams to blank out things which will vary between the two runs, e.g. dates and times. You might want to display the differences in different orders, so you can insert a suitable Sort upstream of RPT.
A related (FBP-specific) problem comes up if C's input streams are not in a predictable sequence, say, because they are the result of a first-come-first-served merge, or if overlapped I/O has been occurring, so some IPs may have overtaken others. The simplest solution is probably to sort them before C sees them, but a better one, if it is feasible, is to mark the IPs at a point where they still have a fixed sequence, so that they can be split apart again before doing the compare. Of course, any processing you do to the differences (after the compare) will be cheaper than processing you do before the compare process (assuming that most of the data has compared equal).
I have given you a very high-speed description of some methodology and implementation techniques which are characteristic of FBP. You will doubtless come up with your own procedures, guidelines and "rules of thumb", and I hope that eventually there will be a community of users of FBP all exchanging ideas and experience (and experiences).... and more books!