Flow-Based Programming - Chap. XIII
Scheduling Rules
|
This chapter has been excerpted from the book "Flow-Based
Programming: A New Approach to Application Development" (van
Nostrand Reinhold,
1994), by J.Paul Morrison.
To find out more about FBP, click on FBP
. This will also tell you how to order a copy.

For definitions of FBP terms, see Glossary
|
Material from book starts here:
So far, we have talked about processes running asynchronously, but
have
not discussed how FBP software manages this feat. This is a key concept
in FBP and we need to understand it thoroughly if we are to design
reliable
structures, and debug them once they have been built! Although this
subject
may appear somewhat forbidding, you will need to grasp it thoroughly to
understand
how this kind of software works. After a bit it will recede into the
background,
and you will only need to work through it consciously when you are
doing
something complex or something unexpected happens. Of course you are at
liberty to skip this chapter, but, if you do, you will probably find
some
of the later chapters a little obscure!
Let us start by looking at the following component pseudo-code (from
a
previous chapter):
receive from IN using a
do while receive has not reached end of data
if c is true
send a to OUT
else
drop a
endif
receive from IN using a
enddo
You will be able to see that the job of this component is to receive
a
stream of IPs and either send them on or destroy them, depending on
some
criterion. As we said above, this code must be run as a separate
process
in our application. We will use the term "component" when talking about
the code; "process" when talking about a particular use of that code.
Before, we were looking at processes and components strictly from a
functional
point of view. Now instead let's look at a component as a piece of
code. Clearly it is well-structured: it has a single entry point and a
single
exit (after the "enddo"). Once it gains control, it performs logic and
calls
subroutines until its input stream is exhausted ("end of data" on IN).
It
is therefore a well-formed subroutine. Subroutines have to be called by
another routine (or by the environment), and at a particular point in
time. So.... what calls our Selector component, and when? The what is
easy: the
Selector component is called by the software which implements FBP,
usually
referred to as the "scheduler". The when is somewhat more complicated:
the
answer is that a component is called as soon as possible after a data
IP
arrives at one of its input ports, or just as soon as possible if there
are
no input ports.
"As soon as possible" means that we do not guarantee that a process
will
start as soon as there is data for it to work on - the CPU may be busy
doing
other things. Normally this isn't a problem - we want to be sure that
our
process has data to work on, not the reverse! If we really needed very
high
responsiveness, we would have to add a priority scheme to our FBP
software. So far, the only implementation of the FBP concepts that I am
aware of that
implemented such a priority scheme was a system written in Japan to
control
railway electric substations (Suzuki et al. 1985). This software built
on
the concepts described in my Systems Journal article, and extended it
to
provide shared high-performance facilities. None of the implementations
I have been involved with have needed this kind of facility.
The other possible start condition is what one would expect if the
process
has no input connections. In this case, one expects the process to be
"self-starting". Another way of looking at this is that a process with
at least one input
connection is delayed until the first data IP arrives. If there are no
input
connections, the process is not delayed. Again, the process will start
some
time after program start time when the CPU is available.
Note that THREADS Initial Information Packets (IIPs) do not count as
input
connections for the purposes of process scheduling - when a process
starts
is determined by the presence or absence of connections with upstream
processes. IIPs are purely passive, and are only "noticed" by the
process when it does
a receive on an IIP port element.
Now we have started our process - this is called "activation", and
the
process is said to be "active". When it gives up control, by executing
its
"end" statement, or by explicitly doing a RETURN, GOBACK, or the
equivalent,
it "deactivates", and its state becomes "inactive".
Now remember that our component kept control by looping until end of
data. Now suppose our component doesn't loop back, but instead just
deactivates
once an IP has been processed. The resulting pseudo-code might look
like
this:
receive from IN using a
if c is true
send a to OUT
else
drop a
endif
We talked about this kind of component in Chapter 9. They are called
"non-loopers". The logic of non-loopers behaves a little differently
from
the preceding version - instead of going back to receive another IP, it
ends
(deactivates) after the "endif". A consequence of this is that the
process's
working storage only exists from activation to deactivation. This means
that it cannot carry ongoing data values across multiple IPs, but, as
we
saw in Chapter 9, the stack can be used for this purpose. A non-looper
becomes
"inactive" after each IP.
What happens now if another data IP arrives at the process's input
port? The process is activated again to process the incoming IP, and
this will
keep happening until the input data stream is exhausted. The process is
activated as many times as there are input IPs. The decision as to when
to deactivate is made within the logic of the component - it is quite
possible
to have a "partial looper" which decides to deactivate itself after
every
five IPs, for example, or on recognizing a particular type of IP. This
"looping"
characteristic of a component is referred to as its "periodicity".
Let us consider an inactive (or not yet initiated) process with two
input
ports: data arrives at one of the ports, so the process is activated.
The
process in question had better do a receive of the activating IP before
deactivating
- otherwise it will just be reactivated. As long as it does not consume
the IP, this will keep happening! If, during testing, your program just
hangs, this may be what is going on - of course, it's easy enough to
detect
once you switch tracing on, as you will see something like this:
Process_A Activated
.
.
Process_A Deactivated with retcode ...
Process_A Activated
.
.
Process_A Deactivated with retcode ...
Process_A Activated
.
.
Process_A Deactivated with retcode ...
Process_A Activated
.
and so on indefinitely!
Our group discussed the possibility of putting checks into the
scheduling
logic to detect this kind of thing, but we never reached a consensus on
what
to do about it, because there are situations where this may be
desirable
behaviour - as long as the activating IP does get consumed eventually.
We
did, however, coin a really horrible piece of jargon: such a component
might
be called a "pathological non-depleter" (you figure it out)! And
besides,
it's really not that hard to debug...
Returning to IIPs, we have said that in THREADS processes read in
IIPs
by doing a receive on their port. If they do a receive again from the
same
port within the lifetime of the process, they get an "end of data"
indication. This means that a component can receive an IIP exactly once
during the lifetime
of the process (from invocation to termination). If a component needs
to
hold onto the IIP across multiple activations, it can use the stack
(described
in Concepts) to hold the IIP, either in the original form in which it
was
received or in a processed form.
So far, we have introduced two basic process states: "active" and
"inactive". We now need terms for the very first activation and the
very last deactivation
of a process: these are called "initiation" and "termination",
respectively. Before initiation, the process doesn't really exist yet
for the FBP software,
so initiation is important as the scheduler has to perform various
kinds
of
initialization logic. Termination is important because the scheduler
must
know
enough not to activate the process again. Termination of a process also
affects
all of its downstream processes, as this determines whether they in
turn
are terminated (a process only terminates when all of its upstream
processes
have terminated).
Processes may thus be thought of as simple machines which can be in
one
of a small number of different "run states". The four main run states
are
the ones we have just described:
-
not yet initiated
-
terminated
-
active
-
inactive
"Not yet initiated" is self-explanatory - it means that the process
has
never received control. All processes start off in this state at the
beginning
of a job step or transaction.
"Terminated" means that the process will never receive control
again. This can only happen if all of a process's upstream connections
have been
closed - each of the input connections of a process can be closed
explicitly
by that process, or it will be closed automatically if all of the
processes
feeding it have terminated.
The underlying idea here is that a process only becomes terminated
if
it can never be activated again. It can never be activated again if
there
is nowhere for more data IPs to come from. Note that, while a
component's
logic decides when to deactivate, termination is controlled by factors
outside
of the process. There is one exception to this, however: a component
can
decide not to be reactivated again, e.g. as a result of some error
condition. It does this in both DFDM and THREADS by returning a
particular return code
value (or higher) to the scheduler. [This has not been implemented in
JavaFBP or C#FBP.] Earlier versions of FBP allowed one
component
to bring down the whole network, but in recent years we felt that this
was
not conceptually sound (parts of the network could be on different
computers),
so now a process can only terminate itself - no process can terminate
another. There is a different way that a component can decide to
terminate itself,
and that is by closing its input ports. Some processes don't have input
ports, but, for those that do, this has the same effect as terminating
with
a high return code.
A simple example will show why this needed: suppose you have a
Reader
process which is reading a file of a few million records, and a
downstream
process crashes: under normal FBP rules, the Reader keeps reading all
the
records, and sending them to its output port. As each send finds the
output
port closed, the Reader has to drop the undeliverable IP. So it has to
read
all the records, requiring a few million each of "create", "send" and
"drop". Instead, it is much better to bring the Reader down as quickly
as possible,
so it can stop tying up time and resources. Readers are therefore
normally
coded so that, the first time they find the output port closed, they
just
deactivate with a high return code. This takes care of any necessary
housekeeping,
and eventually the whole network can close down. By the way, this
practice
makes sense for all components, not just long-running ones - it is good
programming
style for components always to test for unsuccessful sends. If this
condition
is detected, they must decide whether to continue executing, or whether
to
just close down - this usually depends on whether the output port is
related
to the main function of the component, or whether it is optional.
When all the processes in a network have terminated, the network
itself
terminates. Now, it is possible for one process to block another
process
so that the network as a whole cannot come down gracefully. This is
called
a "deadlock" in FBP and is described in some detail in a later chapter.
This is however a design problem, and can always be prevented by proper
design. If the network is properly designed, it will terminate normally
when all
of its processes have terminated, and all resources will then be freed
up.
In Chapter 7, we talked about various kinds of composite components.
DFDM's dynamic subnets and the composite components of FPE had the
ability
to revive terminated processes. In that chapter we explained why this
ability
is necessary, and we shall run into it again in Chapter 20, when we
talk
about Checkpointing. Revived processes essentially go from the
"terminated"
state back to the "not yet initiated" state.
If we had a separate CPU for each process, the above-mentioned four
states
would be enough, although a component waiting to send to a full
connection, waiting to receive from an empty one, or waiting on an
external event, would have to spin waiting for the desired
condition. To avoid this, we have introduced a suspended state,
so we can split
the active state into "normal" and "suspended", resulting in five
states:
-
not yet initiated
-
terminated
-
active normal
-
active suspended
-
inactive
At this point I would like to stress the point that a given process
can
only be in one of these states at a time, and, when suspended, a
process
can only be waiting for a single event. While you will occasionally
feel
that this is too much of a restriction, we deliberately made this
decision
in
order to make an FBP system easier to visualize and work with. At
various
times in the development of FBP systems, we were tempted to allow a
process
to wait on more than one event at a time, but we always found a way
round
it, and never needed to add this ability to our model. Suppose you want
to have a process, P, which
will be triggered by a timer click or by an
IP
arriving at an input port, whichever comes first: the rule about
processes
having a single state suggests that you might need two processes, one
waiting
on each event type. One possible solution, however, is to have one
process
send out an IP on each timer click, and then merge its output stream
with
the IPs arriving from another source, resulting in a single stream
which
is then fed to P. The overhead of the extra processes is outweighed in
our
experience by the reduction in complexity of the mental model and the
consequent
reduction in software complexity and improved performance. Here is a
picture
of the resulting network:
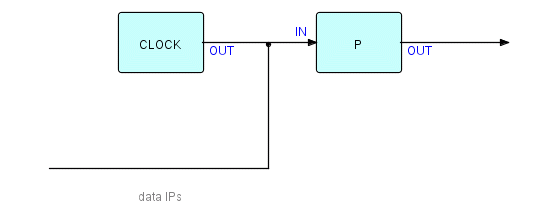
Figure 13.1
Up to now, we have assumed that all ports are named. Not all ports
need
to be known to the components they are attached to: sometimes it is
desirable
to be able to specify connections in the network which the processes
themselves
don't know about. These are especially useful for introducing timing
constraints
into an application without having to add logic to the components
involved. In DFDM we used port 0 for various functions of this kind,
but this idea
has been generalized into what we call automatic ports, to reflect the
idea
that their functioning is not under the component's control.
Consider two processes, one writing a file and one reading it. You,
the
network designer, want to interlock the two components so that the
reader
cannot start until the writer finishes. To do this, you figure that if
you
connect an input port to the reader, the reader will be prevented from
starting
until an IP arrives on that port (by the above scheduling rules). On
the
other hand, readers don't usually have input ports, and if you add one,
the
reader will have to have some additional code to dispose of incoming
IPs,
looking something like this:
if DELAY port connected
receive from DELAY port
discard received IP
endif
Similarly,
you would also have to add code to the Writer at termination time to
send
an "I'm finished" IP to an appropriate output port.
Now, to avoid having to add seldom used code (to put out and receive
these
special signals) to every component in the entire system, the software
should
provide two optional ports for each process which the implementing
component
doesn't know about: an automatic input port and an automatic output
port. If the automatic output port is connected, the FBP scheduler
closes it at termination time.
The automatic input works like this: if there is an automatic input
port connected, process activation is delayed until an IP is received
on
that port, or until the port is closed. This assumes that no data
has arrived at another input port.
Here is a picture of the Writer/Reader situation:
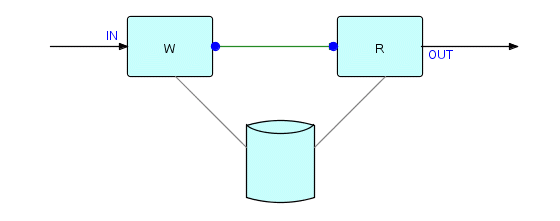
Figure 13.2
where the solid line indicates a connection between W's automatic
output
port and R's automatic input port. The solid circles at each end of
the line indicate automatic ports. Since W only terminates when it has
written the entire file, we can use the automatic output signal to
prevent the Reader from starting too early. An
automatic
port need not only be connected to another automatic port - it can
always
be connected to a regular port, or vice versa. Any IP that has been
received
(by the scheduler) at an automatic input port is automatically
discarded
(better
not use any important data for this job, unless you have taken a copy)!
Here is a network where the automatic output signal gates an IP from
another
process. Assuming that C receives from I1 before it receives from I2,
then
C will not process the input at I2 until A has terminated. If we made
I1
automatic, we would have essentially the same effect, except that C
would
not have to do a receive, but conversely, it would not have the option
of
processing the input at I2 first.
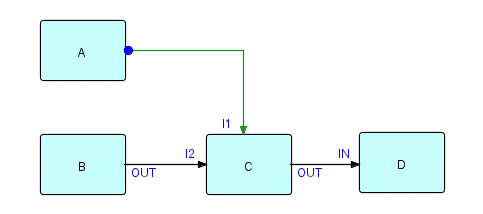
Figure 13.3
There is another situation which is similar to the automatic output
port:
all output ports of a component, whether the component "knows" about
them
or not, will present end of data when that component terminates. This
can
also be used to defer events until one or more processes have
terminated
(see Chapter 20). [This was true in THREADS - this situation is not
allowed in JavaFBP or C#FBP.]
One last topic we should mention is the problem of the "null"
stream:
in DFDM a component receiving a null stream (a stream with no data IPs)
was
invoked anyway. This logic, while perhaps consistent with the regular
scheduling rules, tended to increase run-time costs. In one interactive
application, we found that 2/3 of all the processes were error
handlers,
and so should really never get fired up if no errors occurred. If they
were
fired up, as in the normal DFDM case, the added overhead became quite
expensive
- especially since most of the processes were written in HLLs, so the
run-time
environment of every process had to be initialized separately.
We therefore introduced [in the next implementation] the ability to
change this behaviour for a
whole
network. But then we had the problem of Writers and Counters. Consider
a Writer component writing a disk file: when it receives a null stream,
you
want the Writer to at least open and close its output file, resulting
in
an empty data set. If it doesn't do this, nothing gets changed on the
disk,
and another job reading that file would see the data from the previous
run! Counter components which generate a count IP at end of data have a
similar
problem - how can they generate a count of zero if they are never
invoked? So then we had to add the concept of components which are "end
of stream
sensitive" (components which behave differently in these two modes -
most
do not need to), which could in turn be overridden by a "suppress end
of
stream processing" indication in the network (in case you really didn't
want
this special logic for a particular run).... Old systems which have
been
in use for a number of years tend to develop layers upon layers of
incrustations,
rather like barnacles on a boat....
THREADS defaults the other way from DFDM, but for the cases where
you
want a process receiving a null stream to be activated, THREADS uses
the
concept of "must run at least once". This is an attribute of the
component,
not of the process, and means simply that the component must be
activated
at least once during each run of the network. So Writer and Counter
components
can do their thing, even when receiving a null data stream. [This seems
much simpler! The Java and C# implementations also work this way.]