This chapter has been excerpted from the book "Flow-Based Programming: A New Approach to Application Development" (van Nostrand Reinhold, 1994), by J.Paul Morrison. A second edition (2010) is now available from CreateSpace eStore and Amazon.com. The 2nd edition is also available in e-book format from Kindle (Kindle format) and Lulu (epub format). To find out more about FBP, click on FBP.
For definitions of FBP terms, see Glossary.
|
Material from book starts here:
I am now going to describe some simple applications mixing reusable components and custom ones. We start with a fairly simple text processing application to make a few points about the design of applications in FBP. This is a classical programming problem, originally described by Peter Naur, commonly known as the "Telegram problem". This consists of a simple task, namely to write a program which accepts lines of text and generates output lines of a different length, without splitting any of the words in the text (we assume no word is longer than the size of the output lines). This turns out to be surprisingly hard to do in conventional programming, and therefore is often used as an example in courses on conventional programming. Unless the student realizes that neither the input nor the output logic should be the main line, but the main line has to be a separate piece of code, whose main job is to process a word at a time, the student finds him or herself getting snarled in a lot of confused logic. In FBP, it is much more obvious how to approach the problem, for the following reasons:
-
words are mentioned explicitly in the description of the problem
-
since we have to select our IPs between each pair of processes, it is reasonable for the designer to treat words as IPs somewhere in the implementation of the problem. It would actually be counter-intuitive to deliberately avoid turning words into IPs, given the problem description
-
there is no main line, so the student is not tempted to turn one of the other functions into the main line.
Let us dig into the coding of this problem more deeply. We should have IPs represent words somewhere in the application. You will have realized also that we should have a Read Sequential on the left of the network, reading input records from a file, and a Write Sequential writing the new records onto an output file. Here is a partial network:
Figure 8.1
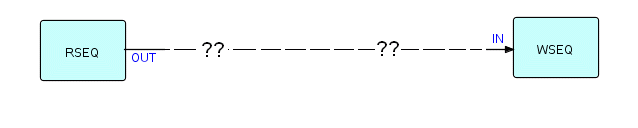
Now the output of Read Sequential and the input of Write Sequential both consist of streams of IPs containing words and blank space, so it seems reasonable that what we need, at minimum, is a component to decompose records into words and a matching one to recompose words back into records. Given the problem as defined, I do not see a need for any more components, but I want to stress at this point that there is no single right answer. Remember ROI? What you select as your basic black boxes depends on how much they are going to be used versus how much it costs to create them.
Let us add our two new components into the picture:
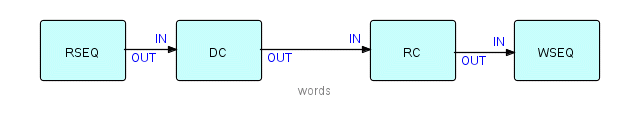
Figure 8.2
Now we have another matched pair of components - in the diagram I have labelled them DC (for DeCompose) and RC for ReCompose). Components can always find out the actual size of any IP, so we do not have to provide the size of the incoming IPs to DC as a parameter. However, RC cannot know what size of IPs we want it to create, so this size must be passed as a parameter to its OPTIONS port (I didn't have to call it that - but it is good a name as any). So let's show an options IIP on RC. RSEQ and WSEQ will also need to know the identifiers of the files they are working with, so our diagram now looks like this:
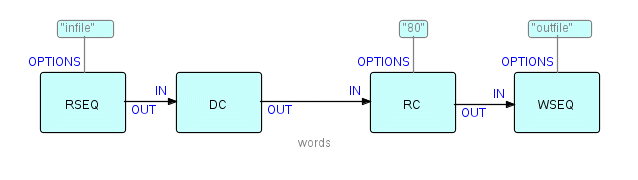
Figure 8.3
For completeness, I will give some possible pseudo-code for DC and RC. Remember that, once you have written and tested DC and RC, you have them forever. So it is worth the effort to get them "perfect" (as close to perfect as software ever gets!). One of the great advantages of FBP is that you can simply insert a Display process on any connection, e.g. between DC and RC, to see if the IPs passing across that connection are correct. So testing is very easy.
In what follows, I have assumed (but not shown in the diagram) that the input port of both components is called IN and the output port is called OUT.
DC (Decompose into Words):
receive from IN using a
do while receive has not reached end of data
do stepping through characters of input IP
if “in word” switch is off and current char non-blank
set “in word” on
save character pointer
endif
if “in word” on and current char blank
set “in word” off
build new string of length =
current pointer - saved pointer)
create IP using new string
send created IP to OUT
endif
enddo
drop a (original input IP)
receive from IN using a
enddo
RC (Recompose Words into Records):
receive output record length from IIP port
drop this IP
create output IP and set it to all blanks
start at beginning of output IP
receive word IP from IN using a
do while receive has not reached end of data
if received word will not fit into output IP
send output IP to OUT
create new output IP and set to all blanks
start at beginning of output IP
endif
move contents of word IP into next space in output IP
if there is room for 1 more character
move in single blank
endif
drop a
receive word IP from IN using a
if receive reached end of data
leave loop
endif
enddo
if output IP has at least one word in it
send output IP to OUT
else
drop it
endif
Maybe this logic can be simplified, but a component does not have to be simple on the inside - it should be simple on the outside, and above all it must work reliably! This point really illustrates a fundamental difference between conventional programming and FBP: I have just shown some pseudocode, and you may be feeling that we are back to conventional programming. However, another way of putting what I am trying to say is that, because we can program, it does not mean that we should. Most conventional programming, and even some of the new Object-Oriented approaches, still stress the production of new code. Many reuse approaches are based on finding what source code is available, and reusing it. Because code is such a malleable medium, and does not have an inherent component structure, we are always creating new stuff and we forget that the results of our work may live long after us and that there is a cost to maintaining them, documenting and managing them. How many times have we heard, "It's less trouble to write my own than to find out what's out there"? In FBP, the orientation is the exact reverse: use what's out there, and only build new if you can justify the effort in terms of ROI. This is where experience becomes valuable: after you have done the same job many times, you know whether other people will find components like DC and RC useful. If you know they won't, find another way to do the job!
Now we have a matched pair of useful components, but, of course, you don't have to use them together all the time. Let's suppose we simply want to count the number of words in a piece of text. We have already mentioned the Count component in the Concepts chapter - it simply counts all its incoming IPs and generates a count IP at the end. It has an option which is substream-sensitive (it generates one count IP for each incoming substream), but for now we will use it in its most basic form. In this form, it simply sends the count it has just calculated out via one output port, while the original incoming IPs are sent out of another one if it is connected (this is an example of an optional port). This type of component is sometimes called a "reference" component, meaning that the original input IPs are passed through unchanged, while some derived information is sent out of another output port. So the resulting structure will look something like this (we won't bother to connect up Count's optional output):
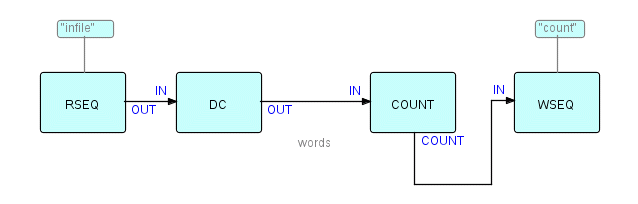
Figure 8.4
We can keep on adding or changing processes indefinitely! These changes may result from changing requirements, new requirements or simply the realization that you can use a component that was developed for one application on another. We talked in the chapter on Reuse about some of the principles behind designing components for reuse.
As another more elaborate example, instead of counting the words, we could decide to sort them, alphabetically or by length. Once we have the words sorted alphabetically, it might be nice to be able to insert fancy heading letters between groups of words starting with the same letters, like some dictionaries.... Of course, once we have sorted them, we should eliminate duplicates. The resulting diagram would then look like this (partially):
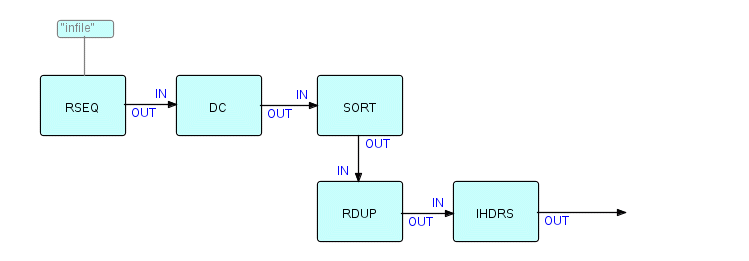
Figure 8.5
where RDUP means "Remove Duplicates" and IHDRS means "Insert Header Letters".
It will come as no surprise that text processing applications have been very productive of generalized components. This is also the application area where the UNIX® system has proven very productive. The UNIX pipe mechanism is very similar to FBP's data streams, except that UNIX communication is based on using streams of characters, whereas FBP's communication is by means of structured IPs.
An excellent example of this kind of text-processing application is P.R. Ewing's publication a few years ago of a Concordance to the Ukrainian Bible (1988) - this was programmed using DFDM, and Philip found DFDM to be very well suited to this type of work. He has recently completed a Biblical Concordance for Xhosa (one of the languages of South Africa), using the PC-based THREADS software. He reports that, after spending between 100 and 150 hours trying to develop this Concordance using conventional (non-FBP) software, he eventually had to abandon it unfinished. With THREADS he was able to produce a completed Concordance with about 40 hours of work (of course this does not include the time needed to input the Bible text). He told me that, as far as he was concerned, the big advantage of FBP is the fact that it simplifies the complexity of an application, and 40 hours vs. more than 100 hours certainly seems to bear this out.
We have used the Sort function as a component a number of times in the foregoing examples. In conventional programming, Sort is usually packaged as a stand-alone utility, although various exits are provided to allow its behaviour to be modified. What are the advantages of packaging it as an FBP component? People very often have the reaction that Sort cannot be a good FBP component because it is too "synchronous" - all the input has to be read in before any of it can be sorted; then the sort proper takes place; then all the sorted records are output by a final merge phase. However, we have found a stream-to-stream sort to be a very effective FBP component for the following reasons:
-
Performance: a Sort which is run as a separate job step has to use files for its input and output, and the control fields have to be in the same place in every input record. If we provide Sort as a stream-to-stream component, then data IPs which are to be sorted no longer have to be written to a file first (and do not have to be retrieved from a file afterwards), but can simply be sent across a connection to the Sort, which in turn sends them on to the next process when it is finished, resulting in a considerable savings in I/O overhead. Actually, the "central" sort phase is the only part of the sort which cannot be overlapped with other processes.
-
Flexibility of positioning control fields: if the control fields are not in a standard place for all the input IPs, you can simply insert a transform process upstream of the Sort to make the key fields line up.
-
Eliminating unnecessary sorting: sometimes, some of the IPs are known to be already sorted, in which case they can bypass the Sort, and be recombined with the sorted IPs later. This is often not practical when the Sort is a separate job step.
-
Improved sorting techniques: if you know something about the characteristics of your keys, you may be able to build more complex networks which perform better than a straight sort. For instance, if you are sorting on a name field, it might make sense to split the data 26 ways, sort each stream independently, then merge them back together - I don't say it will definitely, but you can try it out. The sort process can thus be implemented with other components or subnets for purposes of experimentation.
Although some sorts are faster, a good rule of thumb is that the running time of most sorts is proportional to n.logn, where 'n' is the number of records. Since this is a non-linear relationship, it may be more efficient to split your sort into several separate ones.
Here is a picture of a Sort with some IPs going around it, and with sort tags being generated on the fly by an upstream process (GTAG):
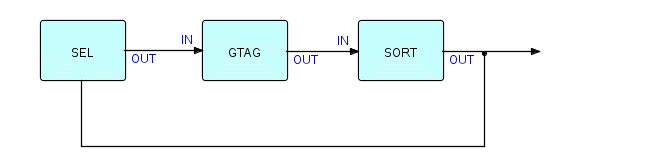
Figure 8.6
Actually Sort is an example of something I discovered quite early in the work on FBP: FBP enables you to tie together things which didn't expect to be tied together! If you can persuade something to accept and generate data packets, it can talk to other things which talk in terms of data. For instance, once you have converted Sort to a stream-to-stream component, it can talk to other utilities, HLLs, DB2, etc. They don't necessarily have to be callable - they just have to be able to accept and generate data once they are given control. I have written networks which contained Assembler, COBOL and PL/I programs, all in the same network. I also built an application which used a screen manager written in Assembler, REXX for all of its calculation logic, used reusable components for screen management and GDDM/PGF for drawing charts when requested by the user. Another network spanned two CMS virtual machines, communicating by means of VMCF. This is a point we'll come back to later: you can design a big network, and then split it across different machines, processors, software systems, etc.
Incidentally, there is a flip side to this ability to tie things together 'without their knowledge': we alluded above to the fact that components have to be reentrant if they are going to multithread with each other. Strange things happen if you try to multithread processes which are not reentrant! After we had turned Sort into a stream-to-stream process, it seemed reasonable to want to run more than one Sort process in a single network. As long as one had fully completed before the other one started, we had no problems. When we tried to overlap two Sorts in time, strange things happened. We suspected that reentrancy was being violated, but it did not consistently cause problems. Some people reported that everything ran fine, others that it always crashed! After we ruled out the possibility that it was programmer-induced, we eventually figured out that some of the sort techniques used by Sort were reentrant (probably the more recent ones), and some not, so some file formats or volumes caused problems (because they triggered different sort techniques), while others did not. We decided that the safest thing to do was interlock the Sorts so that one couldn't start until the other had finished (this is not a great solution as it requires deciding which Sort should run first, which you will probably have realized by now runs counter to the philosophy of FBP).
<>This anecdote reminds me of a pitfall when using Writers to write to PDS's ["Partitioned Data Sets"] under IBM's MVS (even if you are not an MVS user, other operating systems support similar structures, so it may still be instructive). PDS's are data sets which contain a series of subfiles (members), with a directory at the front. A number of programmers used multiple instances of the Writer component in DFDM to try to write more than one member at the same time. What these programmers saw was that the resulting members seemed to have a mixture of each other's data! In MVS, we are so accustomed to treating PDS members as if they were ordinary files that it is not immediately obvious why writing two or more at the same time should cause problems. Of course, the moment it is pointed out, it becomes obvious: PDS's only "grow" at the end. If a PDS already has a member "A", and you decide to write to member "A", what actually happens is that you write the new data at the end of the PDS, and afterwards, when the new member is complete, the directory is updated to point at the new member (leaving what is often referred to as "gas" in the middle [this happens if you are updating a PDS member, or a member has been deleted]). If you try writing to two members concurrently, the two writer processes will see the same "end of PDS", and will both start writing at the same spot. The two processes then write blocks alternately, after which both directory entries are updated to point to the old end of the PDS!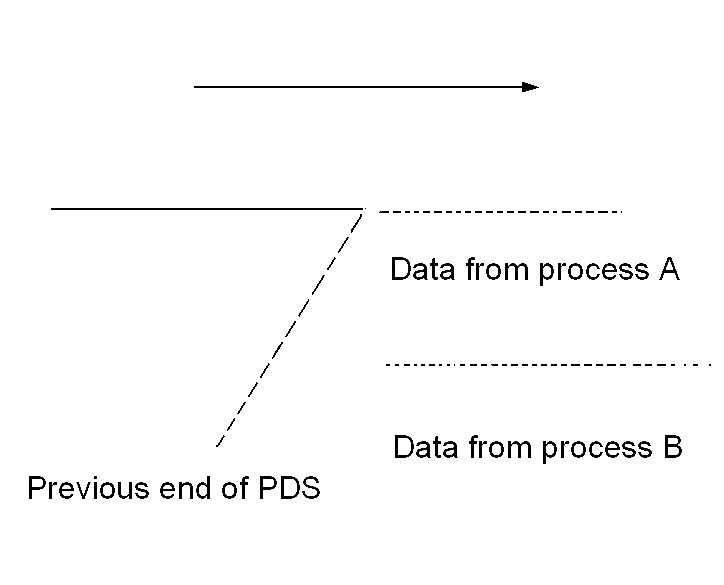
Figure 8.7
Now let's go back to the original Telegram problem, but first we are going to program it using conventional (control-flow) programming. Hopefully the reason for doing this will become clear soon.
From the above discussion, we see that words are the key concept needed to make this problem tractable. Once we realize this, we can go ahead and code it up, using something like the following call hierarchy:
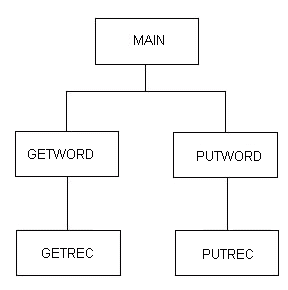
Figure 8.8
As we have said above, it is not at all obvious at first in conventional programming that this is the right way to tackle this job. Most people who tackle this problem start off by making GETWORD or PUTWORD the "boss" program, and promptly get into trouble. So we now realize that we have to "bring in a boss from outside" (call it MAIN), instead of "promoting" GETWORD or PUTWORD to boss. Now MAIN can call GETWORD and PUTWORD to retrieve and store a single word at a time, respectively. To do this GETWORD must in turn call GETREC and PUTWORD must call PUTREC, to look after the I/O. Now note that all four of these subroutines have to "keep their place" in streams of data (streams of words or streams of records). In the old days we did this by writing them all as non-reentrant code, so the place-holder information essentially became global information. This is quite correctly frowned on as poor programming practice, as it has a number of significant disadvantages, so today we normally manage this kind of place-holding logic using the concept of "handles". The general idea (for those of you who haven't had to struggle with this kind of logic) is for MAIN to pass a null handle (in many systems this will be a pointer which is initially set to zero) to GETWORD. When GETWORD sees the null handle, it allocates a block of storage and puts its address into the handle. Thereafter it uses this block of storage indirectly via the handle, and at the end of the run, frees it up again. Although this block of storage is allocated and freed by GETWORD, it is considered to be owned by MAIN. This same logic is also used between MAIN and PUTWORD, between GETWORD and GETREC, and between PUTWORD and PUTREC. At the basic level, our problem is that subroutines cannot maintain internal information which lasts longer than one invocation. In contrast, FBP components are long-running objects which maintain their own internal information. They do not have to be continually reinvoked - you just start them up and they run until their input streams are exhausted. Thus, FBP components can do the same things subroutines do, but in a way that is more robust and, something of considerable interest for our future needs, that is also more distributable. It is important to note that FBP does not prevent us from using subroutines, but my experience is that they are most appropriate for such tasks as mathematical calculations on a few variables, doing look-ups in tables, accessing data bases, and so on - in other words tasks which match as closely as possible the mathematical idea of a function. Such subroutines are said to be "side-effect free", and experience has shown that side-effects are one of the most common causes of programming bugs. Hence subroutines which rely on side-effects for their proper functioning are a pretty poor basis on which to build sophisticated software!
At this point, to get you back in the data flow mood, let's talk about the text-processing example I talked about above. You remember the above example, where we want to take some text, split it into individual words, sort them, remove duplicates, insert fancy letters on every letter change, and print out the result. Oh, and let's print it out in two columns. Using FBP, this is quite simple - actually, we have just described the FBP network structure! I will leave this as an exercise for the reader. It also illustrates a point [the late systems architect] Wayne Stevens has made frequently - namely, that we very often want to string a whole bunch of functions together in a serial manner. We say "do A and B and C and...", which is basically the same as "take the output of A and feed it to B; now take the output of B and feed it to C, and so on..." This is exactly the same as the pipelines of the UNIX system or MS DOS. This is a very natural and important function, and it is essential to be able to express this kind of linkage with a minimum number of key-strokes. In the DFDM and THREADS interpretable notation we use two key-strokes (->) to represent this relationship.
So far, we have worked with quite simple structures which either string together "filters" in what is sometimes called a "string of pearls" pattern, or we had one data stream generate more than one ("divergent" patterns). There is a point to be made about divergent flows: once two streams diverge, they will no longer be synchronized. Some software systems go to a lot of trouble to keep them synchronized, but our experience is that, most of the time, it is not necessary or desirable. There are ways to resynchronize them if you really have to, but you may find it's not worth the trouble! For one thing, in the chapter on deadlocks we will find that resynchronization is a potential cause of deadlocks.
People very often split data streams so that different parts of their networks can handle different IP types - this works best if you do not need to retain any timing relationships between the different types. If you do, there is a variant of the "string of pearls" technique that you may find useful: have each "pearl" look after one IP type and pass all the other ones through. Its (partial) pseudo-code would then look as follows:
receive from port IN using a
if type is XXX
process type XXX
endif
send a to port OUT
You can then string as many of these together as you want and each pearl will look after its own data type and ignore all the others.
Now it's time to talk about various types of Merge function. There is a basic merge built right into FBP - the first-come, first-served merge. This is done very simply by connecting two or more output ports to one input port, as follows:
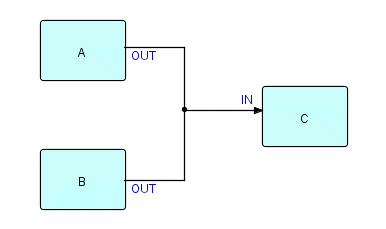
Figure 8.9
where ports OUT of A and OUT of B feed into port IN of C. IPs being sent out along this connection to the IN port of C will arrive interleaved. The IPs sent out by a single process will still arrive in the correct sequence, but their sequencing relative to the output of the other process will be unpredictable. Why would you use this structure? Surprisingly often! C might be a Sort, so the sequence of its incoming IPs is going to be changed anyway. The IPs from the two output streams may be easily distinguishable, so we can always separate them out later. C may be interested in receiving its input data as fast as possible - any additional sequencing may cause delays, and in fact may even cause deadlocks.
Now perhaps the first-come, first-served merge may not be adequate, in which case we will need a process at the junction of the two streams. This may be a custom-coded merge component, or you may be able to use one of the ones supplied with the FBP software, for instance Collate or Concatenate. Both of these use one or more port elements of a single array port to handle their input streams, so we will use this convention. The reason for this is that they can handle any number of input streams up to the implementation maximum. Of course, custom components could call one input port JOE and the other one JIM - it's up to the developer (of course assuming the component's users will put up with it!).
Our diagram now looks like this:
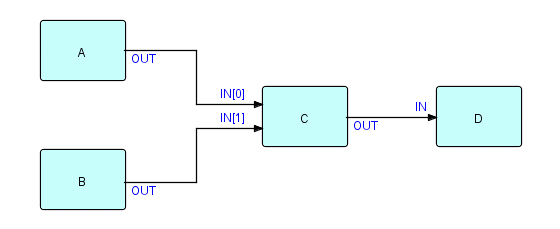
Figure 8.10
Now we have:
-
OUT of A connected to IN[0] of C
-
OUT of B connected to IN[1] of C
-
OUT of C connected to IN D
If C is a Collate, then the output of A will be merged with the output of B according to key values - usually the key fields are specified to Collate by means of option IPs. Alternatively the Collate may use one or more named fields which will be related to the IPs by means of descriptors (see that chapter). One might also visualize Collates which are substream-sensitive - we might want to merge substreams based on a particular field in the first IP of each substream.
Now, if we were to use Concatenate instead of Collate, then what we are saying is that we want C to send all of A's output on to D before it accepts any of B's output. As we said above, there are some situations where this can be useful, too. Collate, however, is a very powerful component, and in conjunction with the ideas described in the next chapter, significantly simplifies application programs which would be extremely complex using conventional programming techniques.