This chapter has been excerpted from the book "Flow-Based Programming: A New Approach to Application Development" (van Nostrand Reinhold, 1994), by J.Paul Morrison. A second edition (2010) is now available from CreateSpace eStore and Amazon.com. The 2nd edition is also available in e-book format from Kindle (Kindle format) and Lulu (epub format). To find out more about FBP, click on FBP.
For definitions of FBP terms, see Glossary.
|
Material from book starts here:
"One of the things I like about AMPS is that there are so many more ways to do a job than with conventional programming" (a programmer at a large Canadian company).
We will start this chapter with the simplest network imaginable - well, actually, a network with one process only is the simplest, but this is equivalent to a conventional program! The simplest network with at least one connection might be a Reader feeding a Writer, as follows:
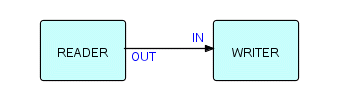
Figure 6.1
This network just copies one file to another, so it is equivalent to the kind of "copy" utility which is provided by just about every operating system. The difference is that FBP lets you combine these utilities into more and more complex functions. Utilities in my experience provide a number of functions, but one always wants something a little different. The functions that they have coded into them are often not the ones one needs. This is quite understandable given the difficulty of predicting what people are going to find useful. One alternative is to combine a bunch of utilities by writing intermediate files out to disk. FBP effectively allows you to combine multiple utility functions without requiring any disk space, or the I/O to read and write from and to disk (so you also use less CPU time, and more importantly, less elapsed time).
Suppose you wanted to combine a "copier" function with a selector, then sort the result before writing it to disk. Just string the functions you want together:
Figure 6.2

Actually, the network doesn't even have to be fully connected. For instance, the following is perfectly valid, and may even be useful!
Figure 6.3
I can remember a time when being able to write a program which would simultaneously read cards and write them to tape, read a tape and punch out the records, and do some printing was considered the height of a programmer's ingenuity! With FBP, I discovered all you have to do is specify the connections between six processes as shown in the diagram!
Now, if you think about this diagram as a way to get something done, not to control when it happens, you will realize that the three pairs of processes shown above do not have to run concurrently. The point is that they can if there are adequate resources available, but they don't have to - it doesn't affect their correct functioning. Think of this network as three train-tracks, with a train running on each one. You just care that each train gets to its destination, not when exactly, nor how fast. In business applications it is correct functioning we care about - not usually the exact timing of events. In the MVS implementations of FBP, the three "tracks" probably will run concurrently because I/O can be overlapped. In THREADS [a PC implementation], which has no I/O overlap yet, they may run sequentially. In none of these cases is the order defined. I think the bottom one will run first, but I'm not sure! Naturally, this makes old-guard programmers very nervous, accustomed as they are to controlling every last detail of when things have to happen. I will keep coming back to this point since it is so important: application development should be concerned with function, not timing control - unless, of course, timing is part of the function, as in some real-time applications. We have to decide what is worth the programmer's attention, and what can safely be left to the machine. Not knowing exactly when things are going to happen turns out to be liberating, rather than disorienting (for most people). But, yes, some programmers will find the transition rather hard!
By the way, when comparing 4GLs and FBP, I have been struck by the fact that you really can do anything in FBP! FBP's power does not come from restricting what programmers can do, but from encapsulating common tasks in reusable components or designs. Since a conventional program is in fact an FBP network consisting of a single process, the programmer is free to ignore all FBP facilities, if s/he wishes, and the result is a conventional program. This may sound glib, but it says to me that we are not taking anything away - we are adding a whole new dimension to the programming process. While some programmers do feel a sense of restriction with FBP, it comes from having to express everything as "black boxes", with well-defined interfaces between them, not from any loss of function.
In the rest of the chapter, we will put together some simple examples using reusable components, but first we should make a catalogue of some of the types of components which an FBP shop will probably have in its collection, a number of which we have already run into. The types which haven't been mentioned above are fairly obvious extensions of what went before. Some of the items in this list should be understood as representing types of component, rather than specific pieces of code. For example, a shop might have two or three Sort modules, with different characteristics.
-
sort
-
collate
-
split
-
assign
-
replicate
-
count
-
concatenate
-
compare
-
generate reports
-
read
-
write
-
transform
-
manipulate text (this might be a large group)
-
discard
Let's also throw in some components which have proven useful during development and debugging: a "dumper" (which displays hex and character formats) and a line-by-line printer component.
We haven't mentioned "Assign" before. I am going to use this for some examples, so we will go into a little more detail on this type of component. This component (or component type) simply plugs a value into a specified position in each incoming IP, and outputs the modified IPs. It has the same shape as a "filter", and can be drawn as follows:
Figure 6.4
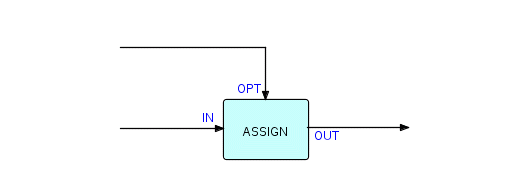
where OPT receives the specification of where in the incoming IPs the modification is to take place, and what value is to be put there. For instance, we might design an Assign component which takes option IPs looking like this:
3,5,ABCDE
This might specify that 'ABCDE' is to be inserted in the 5 characters beginning at offset 3 from the start of each IP. This may seem to be overly simple, but it can be combined with other functions to provide a broad range of function.
By the way, this component illustrates the usefulness of IIPs: if an IIP is attached to the OPT port in Figure 6.4, you have essentially defined a constant assign with the value defined outside the Assign process, but fixed in the network as a whole. Now, instead, connect the OPT port of Assign to an upstream process, and you now have a variable assign, where the values can be anything you want, and can be changed whenever you want.
Now let's use Assign to mark IPs coming from different sources. Let's suppose you want to merge three files and do the same processing on all of them, but you also want to be able to separate them again later. You could use Assign to set a "source code" in the IPs from each file, and use a splitter to separate them later.
In an earlier chapter we have used the idea of a two-way selector, looking like this:
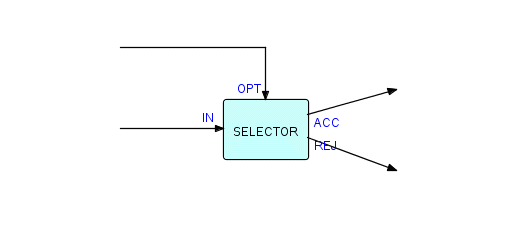
Figure 6.5
Now we can generalize this to an n-way splitter, where, instead of two ports with specific names, we have an array port, which essentially uses a number to designate the actual output connection. Let us show this as follows (using the THREADS numbering convention):
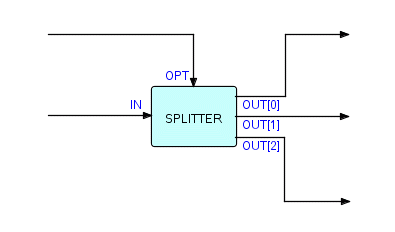
Figure 6.6
Combining the Assign components and a splitter, we could implement the above example of merging three files as follows:
Figure 6.7
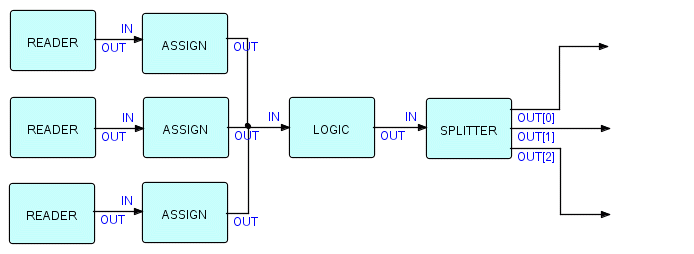
Splitters have to be parametrized by specifying a field length and offset, and a series of possible values. The above splitter might therefore be parametrized as follows:
54,1,'A','B','C'
assuming the codes A, B and C were inserted into the IPs coming from the three readers, respectively.
Let us construct a more complex example based on the provinces of Canada. Let's say we have a file of records with province codes in them. We want to arrange them by time zone, so that we can print them out and have a courier deliver them in time for start of business. The easternmost point in Canada is 4 1/2 hours ahead of the westernmost point, so most big Canadian companies have to wrestle with time zone problems.
Here we will also use a splitter to split the stream of IPs by province. Once the "province" streams have been split out, we could use Assign to insert appropriate codes into the different IP. This splitter might have an option IP looking like this:
6,2,'ON','QU','MA','AL',...
This will be read as follows: check the 2 characters starting at offset 6 from the incoming IP; if it is ON, route the IP to OUT[0]; if QU, to OUT[1]; if MA, to OUT[2]; etc. Of course, in both of the above cases, it would be much more friendly to be able to use field names, rather than offsets and lengths. We will talk about this idea in the chapter on Descriptors.
One other question we have to answer is: what does the Selector do if the incoming IP does not match any of the specified patterns? In DFDM, the standard splitter simply sent unmatched IPs to array element 'n+1', where 'n' equals the number of possible values given (DFDM used 1-based indexing). Another possibility might be to send unmatched IPs to a separate named port.
The application might therefore look like this (I'll just show two Assign processes, and assume all IPs find a match):
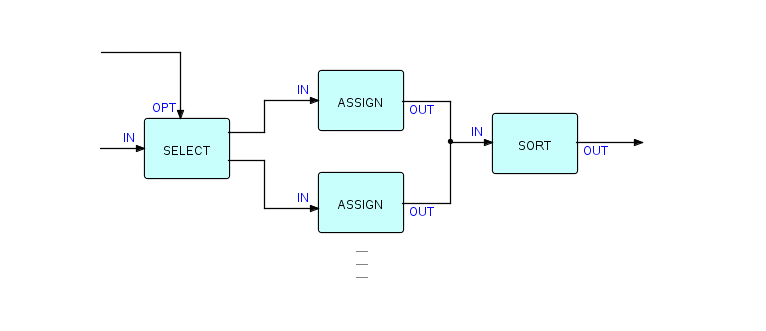
Figure 6.8
The Assigns can insert a code which ascends as one goes from east to west. Because Sort is going to rearrange all the data, we can feed all the modified records into one port on the sort process. This also avoids the possibility of deadlock (I'll be talking more about why this should be so in a later chapter).
I didn't show the option ports on the Assigns, but they will be necessary to specify what codes should be inserted, and where.
Now let's add the logic to handle unmatched IPs. Since they should probably be reported to a human, we will add a printer component, and used the named port technique, as follows:
Figure 6.9
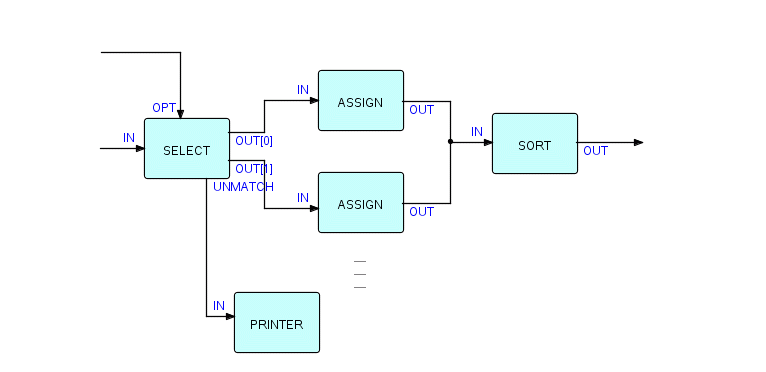
At this point we will simply have a list of unmatched IPs streaming out onto a print file. You will probably want to put out an explanatory title, and do some formatting. You will see later how to do this. For now, let's just say that you will probably need to change this network by inserting one or more processes where I have shown PRINTER above, e.g.:
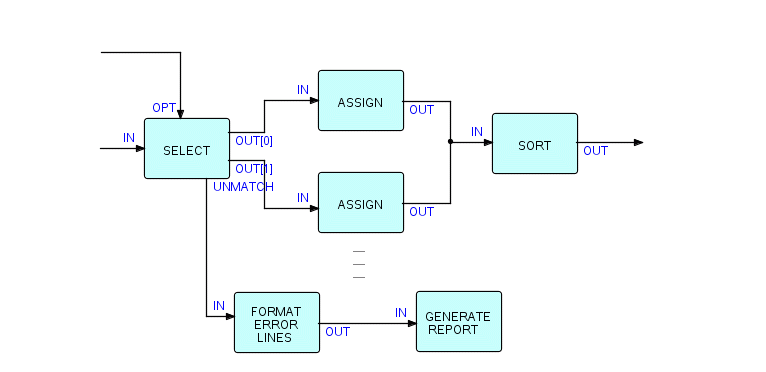
Figure 6.10
Let us suppose we now have our network working and doing what it is supposed to do - we have to ask the question: is this network "industrial strength"? There is a definite temptation, once something is working, to feel the job is finished. In fact, it is quite acceptable to use a program like the one shown above for a once-off utility type of application, or for a temporary bridge between two applications. But there is a fundamental question which the designer must answer, and that is (in this application), how long are there going to be exactly 13 provinces and territories in Canada? No, you did not suddenly jump into a book on Canadian politics! We have made our program structure reflect a part of the structure of the outside world, and we have to decide how comfortable we feel with this dependency. Yes, there will always be programmers, and we can always change this program... provided we can find it! Nobody can make the decision for you, but I would suggest that if this program may have to survive more than a few years, you might want to consider structuring your code to use a separately compiled table or data base, which can pull together all the attributes of provinces of interest to your application. Your application might then look like this (if you generalize SELECT to mean "determine which province it is", and ASSIGN to mean "insert the time zone code for each province"):

Figure 6.11
Note that this diagram has become simpler and the components more complex. It has the same general structure as the preceding diagram, but the shape does not reflect a (possibly changeable) political structure. Another approach might be to amalgamate the SELECT and ASSIGN components shown above, using either special purpose code or a generalized transformer module.
A more subtle generalization might be to keep the parallelism, but not tie it to individual provinces at network specification time. Let us decide there will never be more than, say, 24 provinces, so we will extend the earlier diagram to have 24 ASSIGN processes. SELECT will have 24 port elements on its output port, connected to the ASSIGNs. Now, since both ASSIGN and SELECT are option-driven, we can obtain their parameters from a file (being read by a Reader) or a table (using a Table Look-up component) and send them to their OPT ports. The possibilities are endless! The important decisions are not "how do I get this working?", but "what solution will give me the best balance between performance and maintainability?". When I was teaching FBP concepts, I used to tell my students that the machine will accept almost anything you throw at it - the real challenge in programming is to make your program comprehensible by humans (whether they are other people looking at your code years later, or your own self one week later)! This is far more of a challenge than simply getting the code working.
There is yet another way to look at this example: what we are really doing (in the last diagram) is converting one code to another under control of a table. One of the generalized component types that we found most useful was one (or several) table look-up components. The table could be held as a load module (in MVS), in which case it would have to be maintained by the programming department, but a better technique is to hold it on a file. The table look-up component will then look like this:
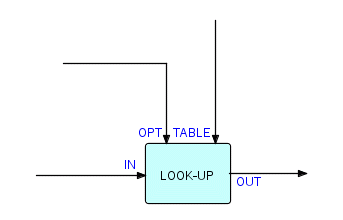
Figure 6.12
What will happen here is that at start-up time the component will read all the IPs from the port named TABLE and build a table in storage. It then starts a process of receiving IPs from IN, looking up a specified field in the table, inserting the found value into the IPs, and then sending them to OUT. Of course, this needs to be parametrized - probably we will need to specify the offset and length of the search field in the incoming IPs, and the offset and length of the field which is to be inserted. We will need a Reader to bring in the table IPs from a file, so the resultant network will look like this (partially):
Figure 6.13
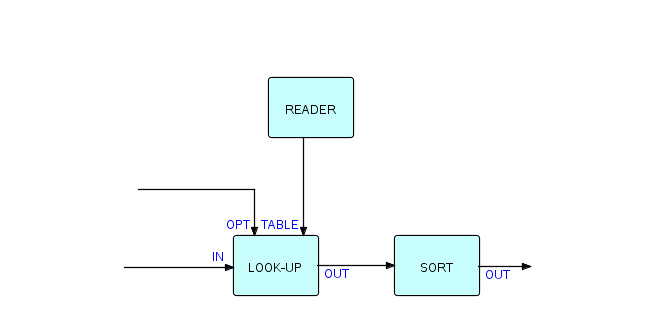
Table look-up components have been found to be very useful in the various dialects of FBP. In DFDM, the system was distributed with two "off the shelf" table look-up components. One of them was much like the one we've just described. However, the other one gives you some idea of what can be provided in the form of reusable code, with a little more imagination! It's pretty complex, but it is a "black box" piece of reusable code, and I am showing it just to indicate what can be done with a single component. Of course it violates some of the rules we gave above, so maybe this should sound some warning bells! However, I believe you will agree that it is still a "stream" process, rather than just a complex algorithm. Basically, it does table look-ups on a table which is being refreshed from some kind of backing store - it doesn't care what kind, so long as the other process conforms to a certain protocol. It therefore acts as both a table look-up component and as a buffering device.
Here is the picture:
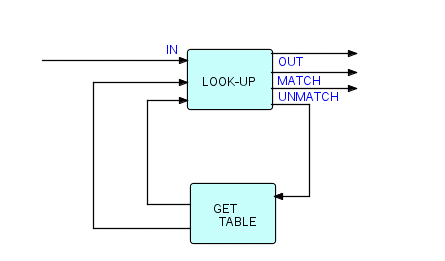
Figure 6.14
This look-up component always works with another process (in this case called GET TABLE) which is used to access a direct access file or data base. These two components work together as follows:
-
the top component builds the table, which starts out empty
-
as each search request comes in, it is checked against the table; if a match is found, the search request goes out of OUT and the table entry out of MATCH
-
if a match is not found, the search request is sent to the other process, which will either find it or not; if it finds it, the search request and the found table entry are sent back to the top component, to be respectively sent to OUT and added to the table
-
if it does not find it, a zero-length IP is sent to the top component, together with the search request; the zero-length IP tells it not to add an entry to the table, and the search request is sent to UNMATCH
This may seem complicated, but once set up, it is very easy to use, and any process can occupy the "bottom" position, provided that it behaves as described. This DFDM component (the "top" component) only needed 4 parameters, of which one was the (optional) maximum number of entries in the table. If this limit was specified, and was reached, entries would start to be dropped off the table in FIFO sequence. Another possibility could have been to use an LRU (Least Recently Used) sequence.
This chapter has tried to give some idea of what can be done using only reusable components. Of course, the number of these is going to grow steadily, and, especially if you have made some of the organizational changes we suggested in an earlier chapter, you may wind up with a sizable number of useful, reusable tools. We don't know what this number is, but my guess is that it will taper off in the low hundreds. The amount these are used will follow a curve with the following general shape:
Figure 6.15
where the less frequently used components may be used only in a few applications. Given this kind of distribution, you may wonder whether it is worth maintaining the low-frequency components in a support department, or whether they should be made the property of the using departments. The answer will depend on whether specialized knowledge is encapsulated in them, whether you are trying to sell them outside the company, and so on.
This kind of rarely used component has similarities with what we have called "custom" components. Until all code is "off the shelf" (if that ever happens), there will be a need for customers to write their own components. This is not as easy as just hooking reusable components together, but it is also pretty straightforward. In the next chapter, I will talk about the idea of composite components, and then in the following chapter start to discuss some concepts for building systems by combining "off the shelf" and "custom" components.